Eu realmente não acredito que estou escrevendo um post sobre Big Brother Brasil.
Ok, respirei fundo, vamos lá…
Sejam bem-vindos a mais um post! Em 2018, um dos projetos mais incríveis que vou tocar é um curso online de Análise de Redes Sociais (ARS) no R a ser oferecido por mim e pelo IBPAD, que é referência nacional em ARS e em outras coisas. A previsão é de que o curso seja lançado até Maio de 2018.
Como um aperitivo do conteúdo a ser abordado no curso, lhes apresento uma simples porém criativa (para quem gosta, né) e prática aplicação de ARS: analisar interações de brothers e sisters (meu Deus, que termos ridículos), descobrir participantes influentes e aplicar algoritmos de detecção de comunidades. Com isso, minha intenção é demonstrar que você pode usar seus conhecimentos em R para aplicar em basicamente qualquer projeto que você quiser.
Uma breve introdução sobre ARS pode ser vista neste artigo na Wikipedia. Se prefere um conteúdo mais elaborado e completo, sugiro adquirir este livro dos caras do IBPAD.
# pacotes usados
library(tidyverse)
library(rvest)
library(igraph)
library(Rfacebook)
library(knitr)
library(viridis)Coleta dos dados
Para preparar os dados para a realização da ARS no R, precisamos obter um dataset neste formato:
tribble(
~pessoa_1, ~pessoa_2,
"Fulano", "Ciclano",
"Fulano", "Beltrano",
"Ciclano", "Beltrano"
)## # A tibble: 3 x 2
## pessoa_1 pessoa_2
## <chr> <chr>
## 1 Fulano Ciclano
## 2 Fulano Beltrano
## 3 Ciclano BeltranoOu seja, o formato desejado é uma simples matriz de 2 colunas onde cada linha representa uma interação entre a Pessoa 1 e a Pessoa 2. A ordem (ex.: Fulano na coluna 1 ou 2) não importa, porque não se trata de uma rede direcionada (directed).
Como, então, obter esses dados?
Existem diversas alternativas. Minha solução foi coletar as manchetes do site do BBB (após me recuperar do desgaste psicológico que é entrar em contato com um material literário tão rico) e extrair os nomes presentes na manchete.
Por exemplo, a partir da “notícia” Diego, Kaysar e Lucas limpam espelho do banheiro, será retornado um dataframe com todas as possíveis combinações de duplas formadas pelos três participantes presentes no título.
Para coletar todas as notícias sobre o BBB já publicadas no site, utilizei a mesma estratégia descrita neste post sobre o G1, ou seja: coletar todos os links já publicados na página do BBB no Facebook.
posts <- getPage("BigBrotherBrasil", token, n = 5000, since = "2018/01/22")
links <- posts$link[posts$type == "link"]Após extrair os links, o código abaixo faz um webscraping bem simples e extrair o título e o corpo das matérias.
extrair_bbb <- function(url){
url <- url %>% read_html()
css_titulo <- ".content-head__title"
css_texto <- ".content-text__container"
noticia_titulo <- url %>%
html_nodes(css = css_titulo) %>%
html_text()
noticia_texto <- url %>%
html_nodes(css = css_texto) %>%
html_text() %>%
dplyr::first()
tibble(noticia_titulo, noticia_texto)
}
lst <- links %>% map(extrair_bbb)# juntar a lista em um dataframe
df_bbb <- bind_rows(lst)
# remover noticias de resumo
df_bbb <- df_bbb %>% filter(!str_detect(noticia_titulo, "Resumo"))
glimpse(df_bbb)## Observations: 595
## Variables: 2
## $ noticia_titulo <chr> "Wagner elogia Gleici: 'Você tá linda'", "Ayrto...
## $ noticia_texto <chr> " Na sala, Gleici chega perto de Wagner e eles ...A seguir, mostro funções para extrair os participantes mencionados nos títulos e retornar as combinações de duplas.
participantes <- c("Ayrton", "Ana Clara", "Ana Paula", "Breno", "Caruso", "Diego",
"Gleici", "Jaqueline", "Jéssica", "Kaysar", "Lucas", "Mahmoud",
"Mara", "Nayara", "Patrícia", "Paula", "Viegas", "Wagner")
extrair_mencionados <- function(x){
participantes[str_detect(x, participantes)]
}
mencionados <- df_bbb$noticia_titulo %>% map(extrair_mencionados)
# manter na lista apenas onde length(.) > 2
mencionados <- mencionados %>% keep(~length(.) > 1)
# gerar lista de combinacoes entre todos os mencionados
gerar_pares <- function(x){
x <- sort(unique(x))
x <- x %>% combn(m = 2, simplify = TRUE) %>% t()
x <- as.tibble(x)
colnames(x) <- c("P1", "P2")
x
}
# exemplo
gerar_pares(c("A", "B", "C"))## # A tibble: 3 x 2
## P1 P2
## <chr> <chr>
## 1 A B
## 2 A C
## 3 B Cdf_mencionados <- mencionados %>%
map(gerar_pares) %>%
bind_rows() %>%
group_by_all() %>%
summarise(n = n())
kable(head(df_mencionados))| P1 | P2 | n |
|---|---|---|
| Ana Clara | Ana Paula | 3 |
| Ana Clara | Ayrton | 11 |
| Ana Clara | Breno | 12 |
| Ana Clara | Caruso | 4 |
| Ana Clara | Diego | 3 |
| Ana Clara | Gleici | 9 |
Visualização dos dados
Antes de partir para ARS, vamos ver como se dá a frequência de interações entre os participantes:
df_mencionados %>%
ggplot(aes(x = P1, y = P2, fill = n)) +
geom_tile() +
viridis::scale_fill_viridis() +
geom_text(aes(label = n), color = "black") +
theme_classic() +
theme(axis.text.x = element_text(angle = 90))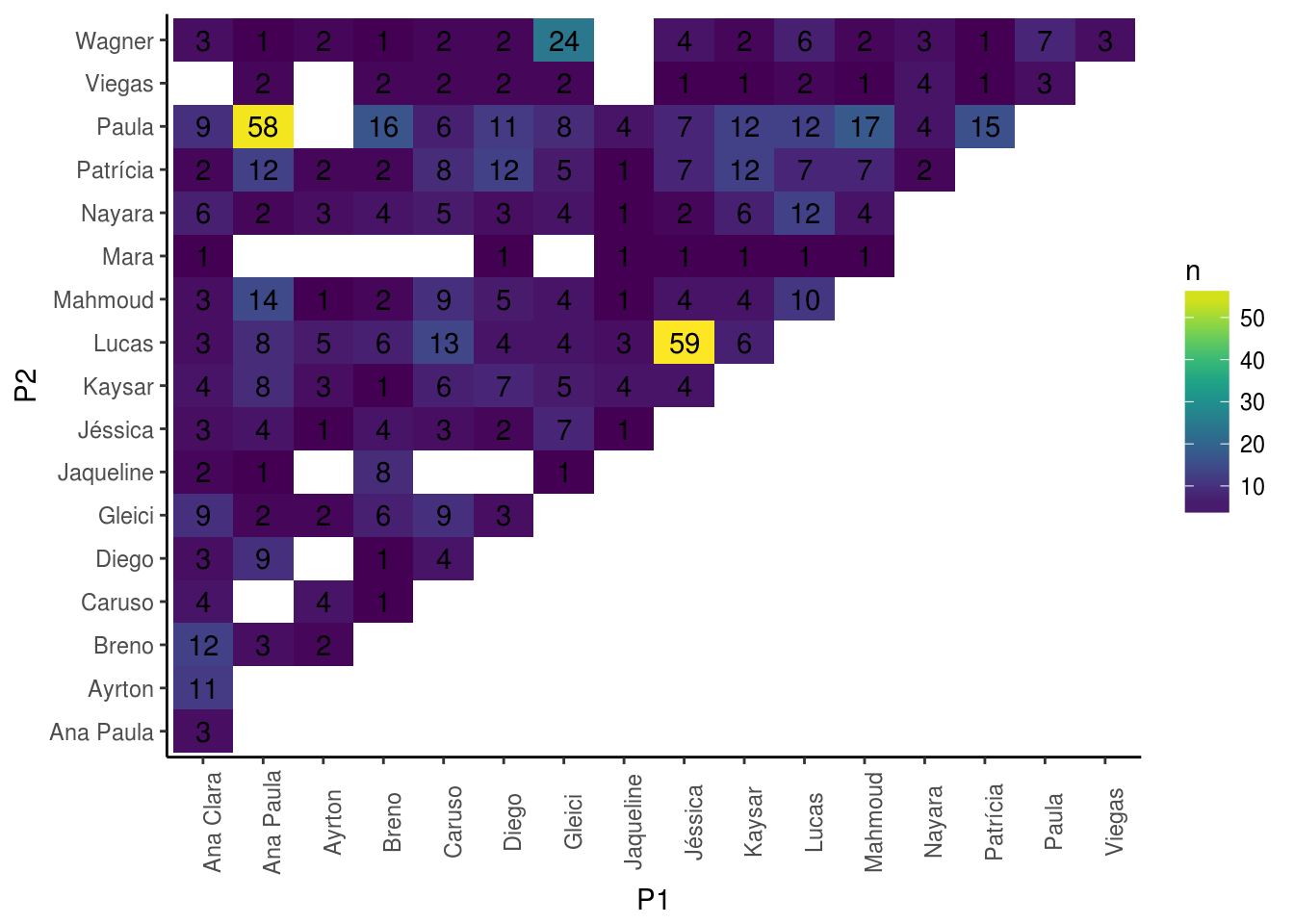
Temos que, praticamente, todo mudo interage com todo mundo. Por isso, antes mesmo de plotar o grafo dessa rede, espera-se que ela seja bem densa, com todos os vértices se ligando.
Entretanto, não deixa de ser interessante notar que, dentro de um grupo de apenas 18 pessoas confinadas em um espaço limitado como uma casa durante algumas semanas ou meses, é incrível como existem pares que simplesmente não interagem entre si (de acordo com a metodologia deste post).
Para deixar a análise interessante, vou remover os nós em que existem menos de 3 interações.
df_mencionados <- df_mencionados %>% filter(n > 3)Análise da Rede
Para definir o grafo, vamos criar um dataframe de metadados sobre os vértices (os participantes), como sexo:
vertices <- tibble(
nome = participantes,
sexo = c("M", "F", "F", "M", "M", "M", "F", "F", "F", "M", "M", "M", "F", "F",
"F", "F", "M", "M")
)
vertices <- vertices %>%
filter(nome %in% df_mencionados$P1 | nome %in% df_mencionados$P2)
g <- graph_from_data_frame(d = df_mencionados, vertices = vertices,
directed = FALSE)
# adicionar cor aos pontos de acordo com o sexo
V(g)$color <- ifelse(V(g)$sexo == "M", "lightblue", "pink")
# adicionar peso aos nós
E(g)$weight <- df_mencionados$n Finalmente, o grafo em si:
set.seed(123)
plot(g, vertex.label.color = "black", layout = layout_with_kk(g),
vertex.size = 20) #,edge.width = E(g)$n/50)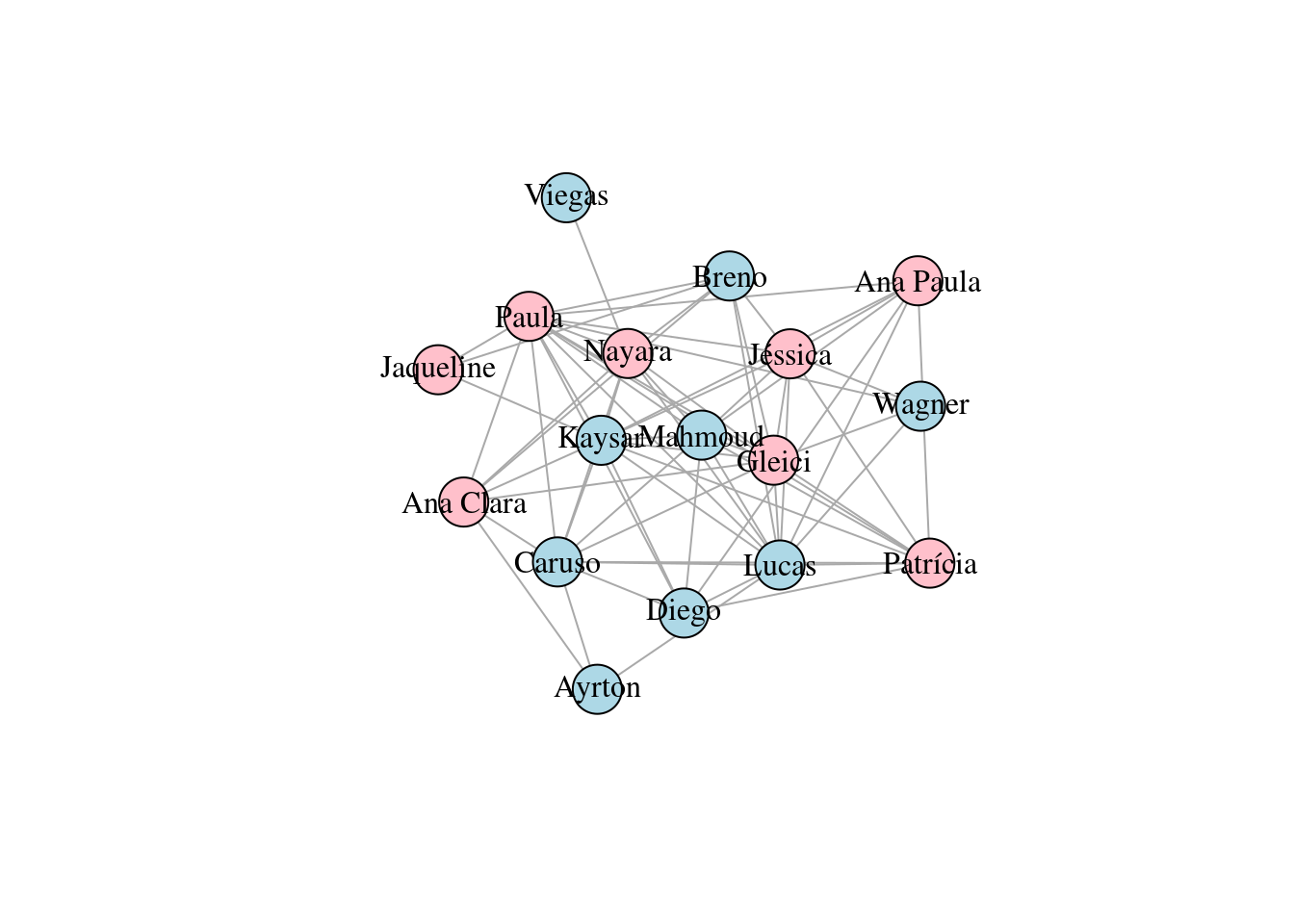
Ok, me tornei o que mais temia, um crítico de BBB, mas vamos lá:
Pela grafo, nota-se que existem alguns participantes mais isolados, como Viegas, Jaqueline e Wagner. Sobre Jaqueline, existe um viés causado pelo tempo, visto que ela já foi eliminada no momento em que vos escrevo.
Outra observação é que de fato existem alguns participantes mais importantes na rede, como Paula, Lucas e Patrícia, visto que estão localizados mais ao centro do grafo.
Uma medida que pode ser usada para mensurar a importância de cada pessoa na rede é o betweenness:
rev(sort(betweenness(g)))## Nayara Kaysar Jéssica Caruso Lucas Gleici
## 21.9166667 16.8333333 16.5000000 13.2500000 9.7500000 9.4166667
## Paula Mahmoud Diego Breno Jaqueline Wagner
## 7.0000000 4.0000000 2.5833333 2.3333333 1.0000000 0.3333333
## Viegas Patrícia Ana Paula Ana Clara Ayrton
## 0.0000000 0.0000000 0.0000000 0.0000000 0.0000000De acordo com essa métrica, Nayara, Kaysar e Jéssica são os brothers com maior articulação entre todos.
Outra medida é o degree, que é simplesmente a contagem de outras pessoas com as quais cada participante está conectado:
rev(sort(degree(g)))## Paula Lucas Kaysar Gleici Mahmoud Caruso Patrícia
## 14 13 12 11 10 10 9
## Nayara Jéssica Diego Breno Ana Paula Ana Clara Wagner
## 9 9 7 7 7 7 4
## Jaqueline Ayrton Viegas
## 3 3 1Uma aplicação muito interessante em ARS é a detecção de comunidade. Com o perdão por não entrar em detalhes sobre o funcionamento do algoritmo (isso eu deixo para meu curso), segue abaixo um exemplo disso:
cluster <- fastgreedy.community(g)
cluster## IGRAPH clustering fast greedy, groups: 3, mod: 0.23
## + groups:
## $`1`
## [1] "Ayrton" "Ana Clara" "Breno" "Caruso" "Gleici"
## [6] "Jaqueline" "Nayara" "Viegas" "Wagner"
##
## $`2`
## [1] "Ana Paula" "Diego" "Kaysar" "Mahmoud" "Patrícia"
## [6] "Paula"
##
## $`3`
## [1] "Jéssica" "Lucas"
## + ... omitted several groups/verticesset.seed(123)
plot(cluster, g)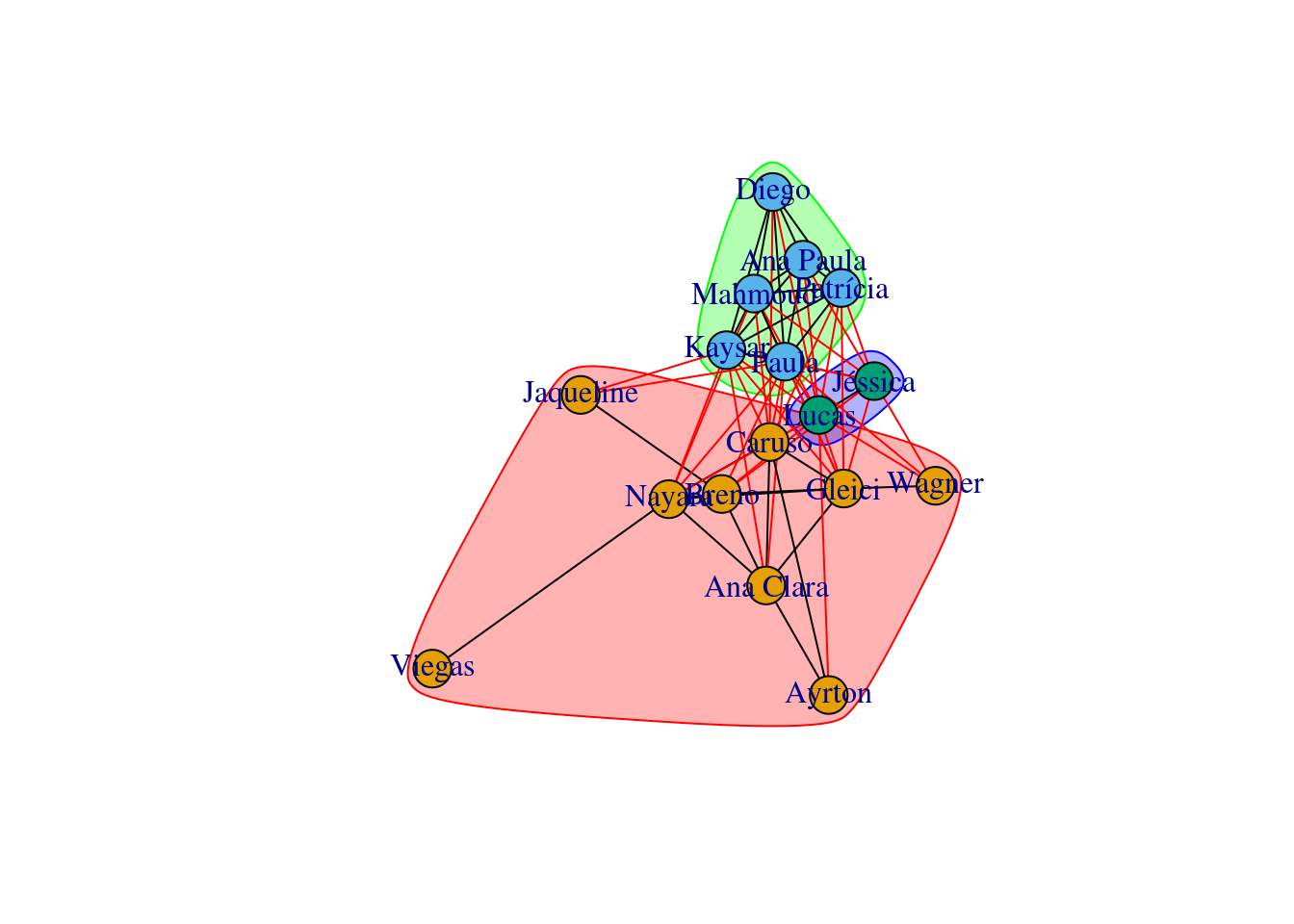
O algoritmno encontrou três comunidades dentro da rede, sendo um deles formados apenas por Jéssica e Lucas.
Conclusão
Você talvez tenha percebido pelo meu tom jocoso no post que não sou lá muito fã de BBB. Contudo, isso não me impediu de pensar nessa aplicação como exemplo de demonstração de situações em que é possível aplicar a Análise de Redes Sociais. Como tudo na vida quando se sabe R, os limites dependem da sua criatividade :)