Recentemente, discuti com um amigo meu que afirmou que Aracaju, cidade onde moramos, é uma capital universitária - ou seja, uma cidade que atrai muitos estudantes de fora -, que eu não acredito que seja verdade. Mas não há melhor maneira de responder a isso senão com análise de dados, não é mesmo?
library(data.table)
library(dplyr)
library(magrittr)
library(gdata)
library(feather)
library(ggplot2)
library(ggthemes)
library(stringr)
library(tidyr)
library(microbenchmark)
library(gridExtra)
library(scales)
library(cowplot)
library(gtable)
library(grid)
library(ggrepel)
setwd("/home/sillas/R/Projetos/CensoEducSuperior/Dados")
Introdução
Os dados que podem tirar essa dúvida, além de trazer a luz muitas outras informações interessantes, são os microdados do Censo da Educação Superior, disponibilizados pelo Instituto Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira, o Inep. Segundo o Portal Brasileiro de Dados:
Anualmente, o Inep realiza a coleta de dados sobre a educação superior, com o objetivo de oferecer informações detalhadas sobre a situação atual e as grandes tendências do setor, tanto à comunidade acadêmica quanto à sociedade em geral. A coleta dos dados tem como referência as diretrizes gerais previstas pelo Decreto nº 6.425 de 4 de abril de 2008. O censo da educação superior reúne informações sobre as instituições de ensino superior, seus cursos de graduação presencial ou a distância, cursos seqüenciais, vagas oferecidas, inscrições, matrículas, ingressantes e concluintes, além de informações sobre docentes, nas diferentes formas de organização acadêmica e categoria administrativa.
Para saber mais: http://www.censosuperior.inep.gov.br/
Os dados mais atualizados disponíveis ao público são de 2014. Neste post, mostrarei todo o processo da análise dos dados, composto por limpeza, manipulação e apresentação dos resultados.
Limpeza de dados
O arquivo principal desta análise, o DM_ALUNO.csv, é um arquivo de 5,4 GB onde as colunas são separadas pelo caractere |. Como só tenho 4 GB de memória RAM em meu notebook, o R não conseguirá importar este arquivo da maneira tradicional. Contudo, não é necessário carregar o arquivo para o R para saber algumas características sobre ele. O dicionário dos microdados, disponível na planilha ANEXO I - 2014, informa que existem 117 colunas no arquivo em questão. Felizmente, para responder a pergunta deste post, só precisamos de quatro colunas:
- CO_IES, que informa o código único de identificação da IES do aluno;
- CO_UF_NASCIMENTO, que informa o código do estado de nascimento do aluno;
- CO_MUNICIPIO_NASCIMENTO, que informa o código do nascimento do aluno;
- ANO_INGRESSO, que informa o ano de ingresso do aluno no curso.
Obs.: Veja que a variável ANO_INGRESSO diz respeito ao aluno que entrou no curso e não na universidade. Como mudanças de curso não são tão frequentes assim e como o volume de dados é muito grande, fazendo com que essas incertezas não prejudiquem o resultado, ignorarei esse detalhe nos resultados.
Para importar apenas essas colunas para o R, a melhor opção foi usar um comando em bash, que é muito mais rápido que o R para tarefas de tratamento de arquivos de texto. O que eu fiz foi criar um novo arquivo, chamado de DM_ALUNO_novo.csv, com apenas essas quatro variáveis:
# colunas importantes: CO_IES (1), UF(40), CO_MUNICIPIO_NASCIMENTO(41), ANO_INGRESSO (117)
# cut_sh <- "cut -d '|' -f 1,40,41,117 DM_ALUNO.csv > DM_ALUNO_novo.csv"
# system.time(system(cut_sh))
# A operação acima leva cerca de 20 segundos para ser executada
# Comparando os dois arquivos:
file.size("DM_ALUNO.csv") %>% humanReadable()
## Error in if (any(x < 0)) stop("'x' must be positive"): missing value where TRUE/FALSE needed
file.size(("DM_ALUNO_novo.csv")) %>% humanReadable()
## Error in if (any(x < 0)) stop("'x' must be positive"): missing value where TRUE/FALSE needed
Assim, o arquivo a ser importado tem apenas 195,5 MB. Contudo, como ele tem muitas linhas, escolhi o pacote data.table para importar e manipular os dados:
system.time(df <- fread("DM_ALUNO_novo.csv"))
## Error in fread("DM_ALUNO_novo.csv"): File 'DM_ALUNO_novo.csv' does not exist. Include one or more spaces to consider the input a system command.
## Timing stopped at: 0 0 0
x = df %>% nrow %>% format(big.mark = ".", decimal.mark = ",")
paste0("Quantidade de linhas do arquivo importado: ", x)
## [1] "Quantidade de linhas do arquivo importado: 8.041.338"
head(df)
## CO_IES CO_UF_NASCIMENTO CO_MUNICIPIO_NASCIMENTO ANO_INGRESSO
## 1: 1 51 5108402 2012
## 2: 1 51 5103403 2012
## 3: 1 51 5103403 2012
## 4: 1 51 5103403 2014
## 5: 1 51 5103403 2011
## 6: 1 51 5103403 2011
## NO_IES SGL_IES DS_CATEGORIA_ADMINISTRATIVA
## 1: UNIVERSIDADE FEDERAL DE MATO GROSSO UFMT Pública Federal
## 2: UNIVERSIDADE FEDERAL DE MATO GROSSO UFMT Pública Federal
## 3: UNIVERSIDADE FEDERAL DE MATO GROSSO UFMT Pública Federal
## 4: UNIVERSIDADE FEDERAL DE MATO GROSSO UFMT Pública Federal
## 5: UNIVERSIDADE FEDERAL DE MATO GROSSO UFMT Pública Federal
## 6: UNIVERSIDADE FEDERAL DE MATO GROSSO UFMT Pública Federal
## CO_MUNICIPIO_IES NO_MUNICIPIO_IES CO_UF_IES SGL_UF_IES NO_REGIAO_IES
## 1: 5103403 Cuiabá 51 MT Centro-Oeste
## 2: 5103403 Cuiabá 51 MT Centro-Oeste
## 3: 5103403 Cuiabá 51 MT Centro-Oeste
## 4: 5103403 Cuiabá 51 MT Centro-Oeste
## 5: 5103403 Cuiabá 51 MT Centro-Oeste
## 6: 5103403 Cuiabá 51 MT Centro-Oeste
## municipioNascimento ufNascimento municipioIES capitalIES
## 1: Várzea Grande (MT) MT Cuiabá (MT) 1
## 2: Cuiabá (MT) MT Cuiabá (MT) 1
## 3: Cuiabá (MT) MT Cuiabá (MT) 1
## 4: Cuiabá (MT) MT Cuiabá (MT) 1
## 5: Cuiabá (MT) MT Cuiabá (MT) 1
## 6: Cuiabá (MT) MT Cuiabá (MT) 1
## municipio_diferente uf_diferente
## 1: 1 0
## 2: 0 0
## 3: 0 0
## 4: 0 0
## 5: 0 0
## 6: 0 0
Com o data.table, o R levou menos de 3 segundos para carregar o arquivo. Já deu para ver que o objeto carregado tem quase 11 milhões de linhas e alguns valores nulos nas colunas referente à UF e ao município de nascimento.
# Percentual de alunos com informação de UF de nascimento inválida
100*sum(is.na(df$CO_UF_NASCIMENTO))/nrow(df)
## [1] 0
# filtrar fora alunos sem informação de UF
df <- df[!is.na(CO_UF_NASCIMENTO)]
Manipulação dos dados
Outro arquivo presente nos microdados é o DM_IES.csv, que traz informações sobre as Instituições de Ensino Superior no Brasil. Para este post, ele será usado como uma tabela suporte ao arquivo principal, que obterá dele informações sobre as IES de cada aluno, como o nome, o estado onde está localizada, o tipo da universidade, etc.
df_ies <- fread("DM_IES.CSV")
## Error in fread("DM_IES.CSV"): File 'DM_IES.CSV' does not exist. Include one or more spaces to consider the input a system command.
# Vendo se funcionou:
names(df_ies)
## Error in eval(expr, envir, enclos): object 'df_ies' not found
# Imprimindo alguns nomes de universidades:
df_ies$NO_IES %>% head
## Error in eval(expr, envir, enclos): object 'df_ies' not found
# Temos que consertar o encoding do arquivo. Para isso, usamos a função iconv
df_ies$NO_IES %<>% iconv(from = "ISO-8859-2", to = "UTF-8")
## Error in eval(expr, envir, enclos): object 'df_ies' not found
# Testando para ver se funcionou:
df_ies$NO_IES %>% head
## Error in eval(expr, envir, enclos): object 'df_ies' not found
# Funcionou! Vamos então fazer o mesmo para outras colunas de texto
df_ies$SGL_IES %<>% iconv(from = "ISO-8859-2", to = "UTF-8")
## Error in eval(expr, envir, enclos): object 'df_ies' not found
df_ies$DS_CATEGORIA_ADMINISTRATIVA %<>% iconv(from = "ISO-8859-2", to = "UTF-8")
## Error in eval(expr, envir, enclos): object 'df_ies' not found
df_ies$NO_MUNICIPIO_IES %<>% iconv(from = "ISO-8859-2", to = "UTF-8")
## Error in eval(expr, envir, enclos): object 'df_ies' not found
# Selecionando apenas colunas úteis para esta análise
df_ies %<>% select(CO_IES, NO_IES, SGL_IES, DS_CATEGORIA_ADMINISTRATIVA, CO_MUNICIPIO_IES,
NO_MUNICIPIO_IES, CO_UF_IES, SGL_UF_IES, NO_REGIAO_IES)
## Error in eval(expr, envir, enclos): object 'df_ies' not found
# juntando todos os arquivos em um só:
df %<>% left_join(df_ies, by = "CO_IES")
## Error in is.data.frame(y): object 'df_ies' not found
rm(df_ies)
## Warning in rm(df_ies): object 'df_ies' not found
# Certificar que o df será tratado como data.table:
setDT(df)
# Nosso df ficou assim:
str(df)
## Classes 'data.table' and 'data.frame': 8041338 obs. of 18 variables:
## $ CO_IES : int 1 1 1 1 1 1 1 1 1 1 ...
## $ CO_UF_NASCIMENTO : int 51 51 51 51 51 51 51 51 51 51 ...
## $ CO_MUNICIPIO_NASCIMENTO : int 5108402 5103403 5103403 5103403 5103403 5103403 5103403 5103403 5103403 5103403 ...
## $ ANO_INGRESSO : int 2012 2012 2012 2014 2011 2011 2010 2010 2011 2010 ...
## $ NO_IES : chr "UNIVERSIDADE FEDERAL DE MATO GROSSO" "UNIVERSIDADE FEDERAL DE MATO GROSSO" "UNIVERSIDADE FEDERAL DE MATO GROSSO" "UNIVERSIDADE FEDERAL DE MATO GROSSO" ...
## $ SGL_IES : chr "UFMT" "UFMT" "UFMT" "UFMT" ...
## $ DS_CATEGORIA_ADMINISTRATIVA: chr "Pública Federal" "Pública Federal" "Pública Federal" "Pública Federal" ...
## $ CO_MUNICIPIO_IES : int 5103403 5103403 5103403 5103403 5103403 5103403 5103403 5103403 5103403 5103403 ...
## $ NO_MUNICIPIO_IES : chr "Cuiabá" "Cuiabá" "Cuiabá" "Cuiabá" ...
## $ CO_UF_IES : int 51 51 51 51 51 51 51 51 51 51 ...
## $ SGL_UF_IES : chr "MT" "MT" "MT" "MT" ...
## $ NO_REGIAO_IES : chr "Centro-Oeste" "Centro-Oeste" "Centro-Oeste" "Centro-Oeste" ...
## $ municipioNascimento : chr "Várzea Grande (MT)" "Cuiabá (MT)" "Cuiabá (MT)" "Cuiabá (MT)" ...
## $ ufNascimento : chr "MT" "MT" "MT" "MT" ...
## $ municipioIES : chr "Cuiabá (MT)" "Cuiabá (MT)" "Cuiabá (MT)" "Cuiabá (MT)" ...
## $ capitalIES : num 1 1 1 1 1 1 1 1 1 1 ...
## $ municipio_diferente : num 1 0 0 0 0 0 0 0 0 0 ...
## $ uf_diferente : num 0 0 0 0 0 0 0 0 0 0 ...
## - attr(*, "sorted")= chr "CO_IES"
## - attr(*, ".internal.selfref")=<externalptr>
# Acrescentar nome do municipio de nascimento
# importar códigos dos municípios brasileiros (tirado do site do IBGE)
df_cidades <- fread("municipiosBR.csv")
## Error in fread("municipiosBR.csv"): File 'municipiosBR.csv' does not exist. Include one or more spaces to consider the input a system command.
names(df_cidades) <- c("uf", "codigo", "nomemunicipio")
# Acrescentar coluna no df original:
df <- df[, municipioNascimento := df_cidades$nomemunicipio[match(CO_MUNICIPIO_NASCIMENTO, df_cidades$codigo)]]
df <- df[, ufNascimento := df_cidades$uf[match(CO_MUNICIPIO_NASCIMENTO, df_cidades$codigo)]]
# Acrescentar UF no nome da cidade
df <- df[, municipioIES := paste0(NO_MUNICIPIO_IES, " (", SGL_UF_IES, ")")]
df <- df[, municipioNascimento := paste0(municipioNascimento, " (", ufNascimento, ")")]
# Adicionar coluna que identifica se cidade é capital
capitaisBR <- c("RIO BRANCO", "MACEIO", "MACAPA", "MANAUS", "SALVADOR", "FORTALEZA", "BRASÍLIA", "VITORIA",
"GOIANIA", "SAO LUIS", "CUIABA", "CAMPO GRANDE", "BELO HORIZONTE", "BELÉM", "JOAO PESSOA",
"CURITIBA", "RECIFE", "TERESINA", "RIO DE JANEIRO", "NATAL", "PORTO ALEGRE", "PORTO VELHO",
"BOA VISTA", "FLORIANOPOLIS", "SAO PAULO", "ARACAJU", "PALMAS"
)
removeracentos <- function(x) iconv(x, to = "ASCII//TRANSLIT")
df <- df[, capitalIES := ifelse(removeracentos(str_to_upper(NO_MUNICIPIO_IES)) %in% capitaisBR, 1, 0)]
Apresentação de dados
Agora já é possível fazer diversas análises possíveis. Vamos então responder a algumas perguntas.
Quantos universitários estudam foram de suas cidades e de seus estados de nascimento?
media <- function(x) (round(100*mean(x), 2))
df <- df[, municipio_diferente := ifelse(CO_MUNICIPIO_IES != CO_MUNICIPIO_NASCIMENTO, 1, 0)]
df <- df[, uf_diferente := ifelse(CO_UF_IES != CO_UF_NASCIMENTO, 1, 0)]
media(df$municipio_diferente)
## [1] 57.38
media(df$uf_diferente)
## [1] 22.83
57,38% dos alunos estudam em uma cidade diferente da que nasceram e 22,83% em um estado diferente.
A distribuição desse índice por cidade e por IES pode ser observada nestes gráficos:
temp1 <- df %>%
tbl_df() %>% # necessário para converter data.table em tbl_df, o formato do dplyr
group_by(CO_MUNICIPIO_IES) %>%
summarise(porc_cidade_dif = media(municipio_diferente), porc_uf_dif = media(uf_diferente)) %>%
gather(referencia, valor, 2:3) %>%
mutate(referencia = factor(referencia, labels = c("Alunos de outra cidade", "Alunos de outro estado")),
estratificacao = "Estratificação por cidade") %>% select(-1)
temp2 <- df %>%
tbl_df() %>% # necessário para converter data.table em tbl_df, o formato do dplyr
group_by(CO_IES) %>%
summarise(porc_cidade_dif = media(municipio_diferente), porc_uf_dif = media(uf_diferente)) %>%
gather(referencia, valor, 2:3) %>%
mutate(referencia = factor(referencia, labels = c("Alunos de outra cidade", "Alunos de outro estado")),
estratificacao = "Estratificação por IES") %>% select(-1)
temp <- rbind(temp1, temp2)
ggplot(temp, aes(x = valor)) +
geom_histogram(binwidth = 5, fill = "#1A476F", color = "black") +
facet_wrap(estratificacao ~ referencia, scales = "free_y") +
scale_x_continuous(breaks = seq(0, 100, 10)) +
theme_bw() +
labs(x = "%", y = "Frequência")
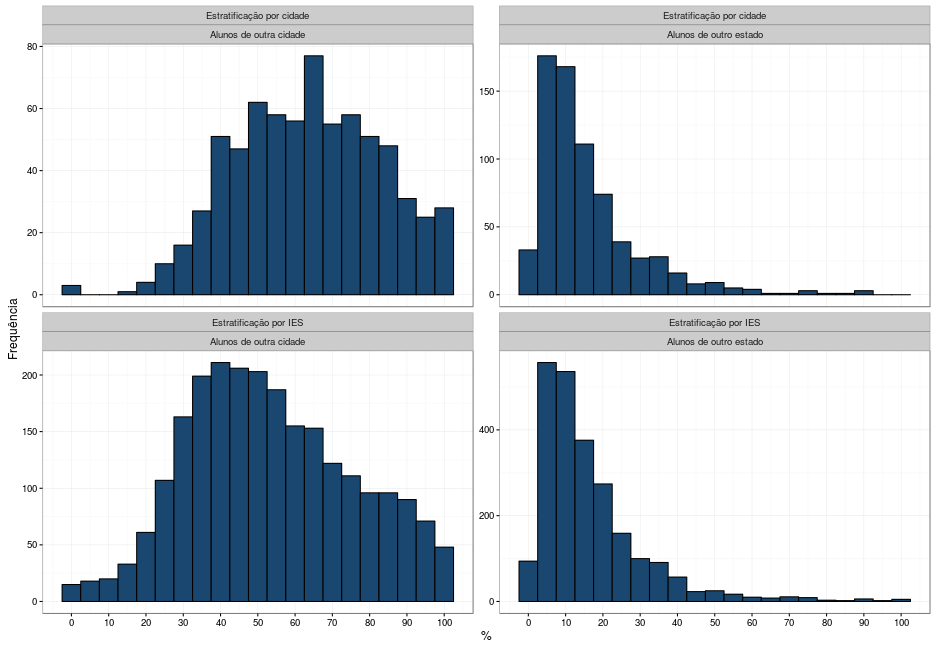
A diferença da distribuição de alunos de outra cidade quando se agrega os resultados por cidade ou por IES é curiosa, a ponto de eu não conseguir formular uma explicação para ela.
Quais são as cidades que mais atraem universitários de outros municípios e estados?
# Definir um vetor de cores para cada região geográfica,
# cada uma terá uma cor fixa, baseada no palette wsj() do pacote ggthemes()
cores <- c("Centro-Oeste" = '#c72e29', 'Nordeste' = '#016392',
'Norte' = '#be9c2e', 'Sudeste' = '#098154', 'Sul' = '#fb832d')
#p1 = percentual de aluno de outros municipios
p1 <- df %>% tbl_df() %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_municipio = media(municipio_diferente)) %>%
ungroup() %>%
top_n(9, porc_municipio) %>%
ggplot(aes(x = reorder(municipioIES, porc_municipio), y = porc_municipio, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
scale_y_continuous(limits = c(0, 100)) +
theme(panel.border = element_blank()) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Cidades com maior porcentual \nde universitários de cidades diferentes", fill = "Região")
# p2: percentual de aluno de outros estados
p2 <- df %>% tbl_df() %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_uf = media(uf_diferente)) %>%
ungroup() %>%
top_n(9, porc_uf) %>%
ggplot(aes(x = reorder(municipioIES, porc_uf), y = porc_uf, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
scale_y_continuous(limits = c(0, 100)) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Cidades com maior porcentual \nde universitários de estados diferentes", fill = "Região") +
theme(panel.border = element_blank())
# p1 com apenas capitais
p3 <- df %>% tbl_df() %>%
filter(capitalIES == 1) %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_municipio = media(municipio_diferente)) %>%
ungroup() %>%
top_n(9, porc_municipio) %>%
ggplot(aes(x = reorder(municipioIES, porc_municipio), y = porc_municipio, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
scale_y_continuous(limits = c(0, 100)) +
theme(panel.border = element_blank()) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Capitais com maior porcentual \nde universitários de cidades diferentes", fill = "Região")
# p2 com apenas capitais
p4 <- df %>% tbl_df() %>%
filter(capitalIES == 1) %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_uf = media(uf_diferente)) %>%
ungroup() %>%
top_n(9, porc_uf) %>%
ggplot(aes(x = reorder(municipioIES, porc_uf), y = porc_uf, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
scale_y_continuous(limits = c(0, 100)) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Capitais com maior porcentual \nde universitários de estados diferentes", fill = "Região") +
theme(panel.border = element_blank())
Para isso, uma novidade aqui no blog: será usado o pacote cowplot para juntar quatro diferentes gráficos em uma imagem só.
# juntar quatro gráficos em um só
# Retira a legenda dos gráficos (para não ficar redundante) e
# reduz a margem da direita e da esquerda para reduzir o espaço vazio
p1 <- p1 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
p2 <- p2 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
p3 <- p3 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
p4 <- p4 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
prow <- plot_grid(p1, p3, p2, p4, align = "vh", nrow = 2)
# plotar legenda embaixo dos 4 gráficos
grobs <- ggplotGrob(p3 + theme(legend.position="bottom"))$grobs
legend_b <- grobs[[which(sapply(grobs, function(x) x$name) == "guide-box")]]
# adicionar anotação:
p <- add_sub(prow, "Em % dos universitários da cidade")
p <- plot_grid(p, legend_b, ncol = 1, rel_heights = c(1, .2))
ggdraw(p)
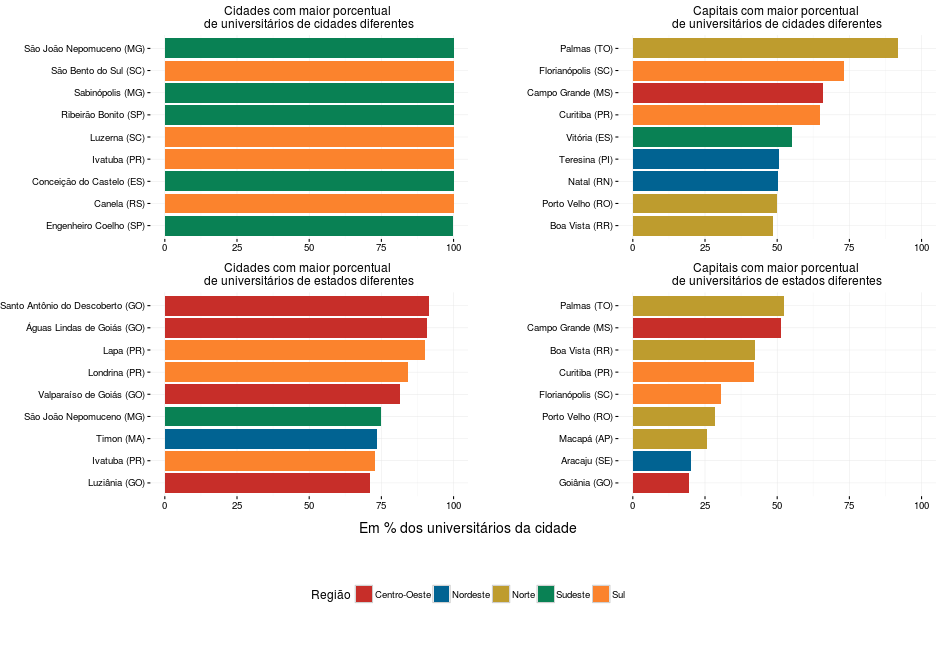
Ou seja: para as 10 cidades com o maior porcentual de alunos de fora do município, esse valor é de 100%. O histograma dessa distribuição mostra que esse resultado não é surpreendente, pois existem mais de 20 cidades que têm no mínimo 95% de alunos de outra cidade. Já quando se trata de analisar as cidades que mais atraem universitários de outros estados, quatro cidades goianas e três paranaenses despontam como capitais universitárias. Surpreendentemente (ao menos para mim), apenas uma cidade do Sudeste consta nesse Top 10. Dentre as capitais, Palmas e Campo Grande se destacam como pólos universitários.
Possivelmente, o resultado será diferente se considerarmos, ao invés da quantidade relativa, o número absoluto de universitários, que é o que é feito abaixo:
#p1 = percentual de aluno de outros municipios
p1 <- df %>% tbl_df() %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_municipio = sum(municipio_diferente)/1000) %>%
ungroup() %>%
top_n(9, porc_municipio) %>%
ggplot(aes(x = reorder(municipioIES, porc_municipio), y = porc_municipio, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
scale_y_continuous(labels = comma) +
theme(panel.border = element_blank()) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Cidades com maior número\nde universitários de cidades diferentes", fill = "Região")
# p2: percentual de aluno de outros estados
p2 <- df %>% tbl_df() %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_uf = sum(uf_diferente)/1000) %>%
ungroup() %>%
top_n(9, porc_uf) %>%
ggplot(aes(x = reorder(municipioIES, porc_uf), y = porc_uf, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Cidades com maior número\nde universitários de estados diferentes", fill = "Região") +
theme(panel.border = element_blank())
# p1 com apenas capitais
p3 <- df %>% tbl_df() %>%
filter(capitalIES == 1) %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_municipio = sum(municipio_diferente)/1000) %>%
ungroup() %>%
top_n(9, porc_municipio) %>%
ggplot(aes(x = reorder(municipioIES, porc_municipio), y = porc_municipio, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
theme(panel.border = element_blank()) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Capitais com maior número\nde universitários de cidades diferentes", fill = "Região")
# p2 com apenas capitais
p4 <- df %>% tbl_df() %>%
filter(capitalIES == 1) %>%
group_by(municipioIES, NO_REGIAO_IES) %>%
summarise(porc_uf = sum(uf_diferente)/1000) %>%
ungroup() %>%
top_n(9, porc_uf) %>%
ggplot(aes(x = reorder(municipioIES, porc_uf), y = porc_uf, fill = NO_REGIAO_IES)) +
geom_bar(stat = "identity") +
scale_fill_manual(values = cores) +
theme_bw() +
coord_flip() +
labs(x = NULL, y = NULL,
title = "Capitais com maior número\nde universitários de estados diferentes", fill = "Região") +
theme(panel.border = element_blank())
# acrescentar quatro gráficos em um só
p1 <- p1 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
p2 <- p2 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
p3 <- p3 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
p4 <- p4 + theme(legend.position = "none", plot.margin = unit(c(6, 0, 6, 0), "pt"), plot.title = element_text(size = 12))
prow <- plot_grid(p1, p3, p2, p4, align = "vh", vjust = 30, nrow = 2)
grobs <- ggplotGrob(p3 + theme(legend.position="bottom"))$grobs
legend_b <- grobs[[which(sapply(grobs, function(x) x$name) == "guide-box")]]
p <- add_sub(prow, "Em milhares de universitários")
p <- plot_grid(p, legend_b, ncol = 1, rel_heights = c(1, .2))
ggdraw(p)
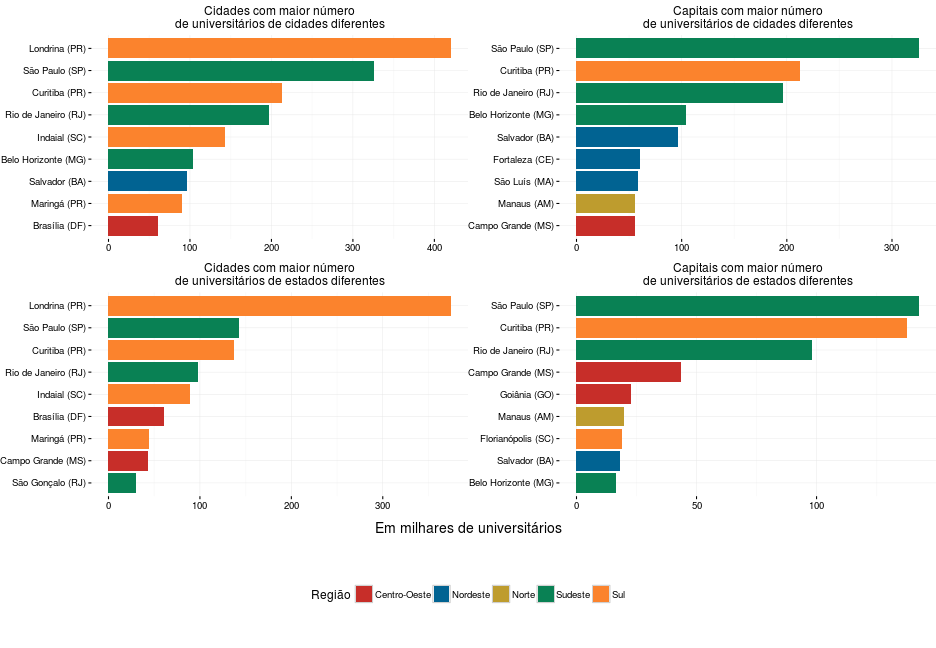
Já que analisamos os resultados por cidade, podemos fazer o mesmo por estado: quais UFs recebem mais estudantes de outros estados?
p <- df[, list(num_absoluto = sum(uf_diferente)/1000, porcentual = media(uf_diferente)), by = .(SGL_UF_IES, NO_REGIAO_IES)]
ggplot(p, aes(x = num_absoluto, y = porcentual, color = NO_REGIAO_IES, label = SGL_UF_IES)) +
geom_point() +
geom_text_repel() +
scale_x_continuous(labels = comma) +
scale_color_manual(values = cores) +
labs(x = "Quantidade absoluta (milhares)",
y = "% dos estudantes que são de outro estado",
title = "Quantidade absoluta e porcentual do total de universitários de \noutros estados para cada UF",
color = "Região") +
theme_minimal() + theme(legend.position = "right")
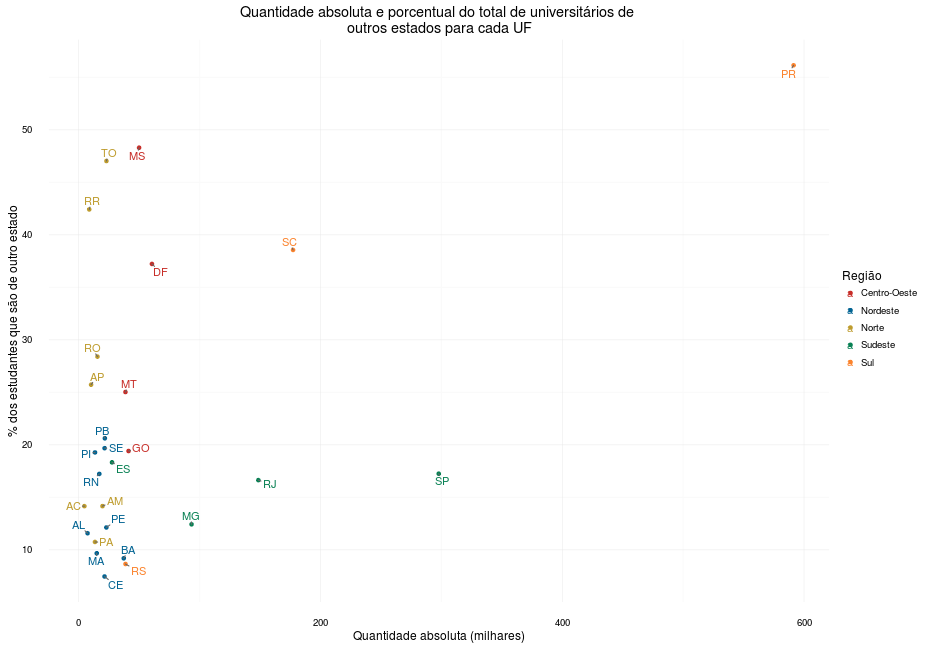
O estado do Paraná é disparado o campeão nesse quesito em ambos os critérios, isto é, tanto por quantidade absoluta - cerca de 600.000 universitários de outras partes do Brasil estudam na Rússia brasileira - como por porcentual - aquela quantidade corresponde a cerca de 55% do total de estudantes matriculados em universidades paranaenses. Na outra ponta do gráfico, a ponta inferior esquerda, a maioria dos estados são da região Nordeste e Norte, com destaque negativo para Maranhão, Alagoas e Bahia, três dos estados mais pobres do país. Arrisco dizer que, por serem mais pobres que a média nacional, as universidades desses estados não têm reputação suficiente para atrair universitários de outros estados do Brasil.
Conclusão
Este é o fim de mais um post. No próximo post, falarei sobre o efeito do Enem no movimento migracional
# Salvar o arquivo para posteriores análises:
write_feather(df, "dm_aluno_tratado.feather")