Paixão por Dados de cara nova!
O blog está de cara nova! O endereço antigo do blog começou a apresentar alguns bugs bem chatos, então tomei a decisão de finalmente migrar para uma nova plataforma, utilizando o pacote blogdown, a mesma que o pessoal do Curso-R usa no site deles. Para comemorar essa migração, anuncio o lançamento do meu terceiro pacote R: o literaturaBR.
literaturaBR, o mais novo pacote da comunidade R Brasil
Após lançar o pacote lexiconPT, senti que a carência de datasets textuais na língua portuguesa poderia restringir seu potencial de alcance de desenvolvedores e cientistas de dados interessados em usar os léxicos para fazer análise de sentimento. Apesar de ter feito um post mostrando seu uso em dados obtidos do Facebook, eu admito que é complicado ter que fazer web scraping de algum site toda vez que se deseja praticar ou ensinar mineração de texto com textos em Português.
Esse problema me inspirou a desenvolver mais um pacote R para facilitar pequenas demonstrações de Text Mining. Assim como a Julia Silge criou o janeaustenr com livros clássicos da Jane Austen, eu criei o literaturaBR, um data package criado para disponibilizar livros clássicos da literatura brasileira já prontos para serem importados e manuseados no R. Para saber quais livros estão disponíveis na versão atual do pacote e outras informações úteis, visite seu repositório.
Este post se destina a apresentar algumas exemplos simples de tarefas de Text Mining, como:
* Análise de Sentimento;
* Complexidade Léxica;
* Analise de ocorrência de palavras em específico.
Introdução
Os pacotes usados neste post são:
library(literaturaBR) # meio obvio
library(tidytext) # excelente pacote de text mining
library(tidyverse) # <3
library(stringr) # indispensavel para manipulacao de texto
library(quanteda) # otimas funcoes para analise quantitativa de texto
library(qdap) # similar ao quanteda, embo ra eu nao me lembre exatamente se eu o uso neste post
library(forcats) # manipulacao de fatores
library(ggthemes) # temas para o ggplot2
library(lexiconPT)Vamos então importar os datasets presentes no literaturaBR na data de hoje e os transformar em um dataset só:
data("memorias_de_um_sargento_de_milicias")
data("memorias_postumas_bras_cubas")
data("alienista")
data("escrava_isaura")
data("ateneu")
df <- bind_rows(memorias_de_um_sargento_de_milicias,
memorias_postumas_bras_cubas,
alienista,
escrava_isaura,
ateneu)
# Olhando a estrutura do dataframe
glimpse(df)## Observations: 5,149
## Variables: 5
## $ book_name <chr> "Memórias de um Sargento de Milícias", "Memór...
## $ chapter_name <chr> "Capítulo 1 - Origem, nascimento e batismo", ...
## $ url <chr> "https://pt.wikisource.org/wiki/Mem%C3%B3rias...
## $ paragraph_number <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, ...
## $ text <chr> "Era no tempo do rei.", "Uma das quatro esqui...Todos os datasets fornecidos pelo literaturaBR possuem a mesma estrutura, onde cada linha corresponde a um parágrafo de um livro e contêm 5 variáveis:
* book_name: Nome original do livro;
* chapter_name: Nome original do capítulo do livro do parágrafo;
* url: Link para artigo do Wikisouce de onde o capítulo do parágrafo foi extraído;
* paragraph_number: Ordem do parágrafo em seu capítulo;
* text: Texto do parágrafo. Contem acentos e pontuação.
Um rápido adendo: os nomes das colunas está em inglês porque só tomei a decisão de escrever toda a documentação do pacote em Português meio tardiamente.
Análise básica
Para usar (parte) das funções do pacote quanteda, precisamos converter o dataframe dos livros em um objeto do tipo corpus.
df_corpus <- df %>%
# agrupar por livro
group_by(book_name) %>%
# formatar o dataframe para que so tenha uma linha por livro
summarise(text = paste0(text, sep = "", collapse = ". "))
dim(df_corpus)## [1] 5 2meu_corpus <- quanteda::corpus(df_corpus$text, docnames = df_corpus$book_name)
summary(meu_corpus)## Corpus consisting of 5 documents:
##
## Text Types Tokens Sentences
## A escrava Isaura 9349 64929 1751
## Memórias de um Sargento de Milícias 8703 71391 2287
## Memórias Póstumas de Brás Cubas 11058 74223 3199
## O Alienista 4387 19977 770
## O Ateneu 15341 73063 3551
##
## Source: /home/sillas/R/Projetos/paixaopordados-blogdown/content/post/* on x86_64 by sillas
## Created: Wed Nov 22 20:34:35 2017
## Notes:Como vemos, a função quanteda::corpus() identificou a quantidade de Types (número de palavras distintas em um corpus), Tokens (número total de palavras em um corpus) e Sentences (frases) em cada livro.
Vamos então criar uma document-feature matrix a partir desse corpus criado, tomando o cuidade de remover pontuações e stopwords:
corpus_dfm <- dfm(meu_corpus, remove_punct = TRUE,
remove = quanteda::stopwords("portuguese"),
groups = df_corpus$book_name)
# Analisando as 15 palavras mais comuns no geral por livro
dfm_sort(corpus_dfm)[, 1:15]## Document-feature matrix of: 5 documents, 15 features (5.33% sparse).
## 5 x 15 sparse Matrix of class "dfm"
## features
## docs é casa tempo ainda tudo bem todos
## A escrava Isaura 424 98 81 121 78 175 78
## Memórias de um Sargento de Milícias 305 193 207 131 192 126 139
## Memórias Póstumas de Brás Cubas 492 107 108 89 98 65 69
## O Alienista 88 108 20 29 26 10 37
## O Ateneu 199 51 56 97 56 56 91
## features
## docs tão ser havia d leonardo coisa
## A escrava Isaura 137 96 56 20 0 35
## Memórias de um Sargento de Milícias 63 75 153 194 366 128
## Memórias Póstumas de Brás Cubas 95 97 53 83 0 140
## O Alienista 31 25 7 44 0 23
## O Ateneu 47 78 101 26 0 38
## features
## docs disse dia
## A escrava Isaura 67 41
## Memórias de um Sargento de Milícias 119 128
## Memórias Póstumas de Brás Cubas 130 89
## O Alienista 30 21
## O Ateneu 11 77A função dfm_sort() retorna a ocorrência de cada palavra (também chamado de token ou feature) em cada livro. Para pesquisar a ocorrência de alguma palavra específica nos documentos, use a função dfm_select():
# ocorrencias da palavra amor
dfm_select(corpus_dfm, "amor")## Document-feature matrix of: 5 documents, 1 feature (0% sparse).
## 5 x 1 sparse Matrix of class "dfm"
## features
## docs amor
## A escrava Isaura 71
## Memórias de um Sargento de Milícias 30
## Memórias Póstumas de Brás Cubas 53
## O Alienista 3
## O Ateneu 45Curioso para saber o contexto em que essa palavra aparece? Você pode usar a função kwic() para isso:
# usar a função head() para o output nao ficar mt grande
kwic(meu_corpus, "amor") %>% head()##
## [A escrava Isaura, 2011] , bem pode conquistar o | amor |
## [A escrava Isaura, 5090] não se havia casado por | amor |
## [A escrava Isaura, 5173] o mais cego e violento | amor |
## [A escrava Isaura, 6555] pudesse obter também o teu | amor |
## [A escrava Isaura, 7215] Ora, senhor, pelo | amor |
## [A escrava Isaura, 7686] disputar com o senhor por | amor |
##
## de algum guapo mocetão,
## , sentimento esse a que
## , que de dia em
## !... És
## de Deus!..
## de uma escrava..Para saber as palavras mais usadas, dentre os vários métodos possíveis para isso, pode-se usar a função topfeatures()
topfeatures(corpus_dfm, groups = df_corpus$book_name)## $`A escrava Isaura`
## é isaura senhor leôncio álvaro escrava bem tão pai
## 424 344 243 205 188 180 175 137 127
## ainda
## 121
##
## $`Memórias de um Sargento de Milícias`
## leonardo é maria comadre tempo porém d casa
## 366 305 231 209 207 205 194 193
## tudo major
## 192 179
##
## $`Memórias Póstumas de Brás Cubas`
## é virgília coisa olhos disse nada outro outra
## 492 199 140 138 130 125 122 116
## vida porque
## 116 113
##
## $`O Alienista`
## casa alienista é verde bacamarte barbeiro câmara
## 108 106 88 77 59 54 52
## itaguaí simão evarista
## 49 49 45
##
## $`O Ateneu`
## é sobre aristarco diretor havia ainda ateneu
## 199 167 148 104 101 97 93
## todos ser dois
## 91 78 77Análise comparativa entre os livros
Algo interessante a se fazer é quantificar a similaridade e a dissimilaridade ou distância entre os livros. As funções textstat_simil e textstat_dist implementam diversas técnicas e algoritmos para isso. Sugiro ler a documentação completa das funções e ler as referências indicadas para conhecer melhor os métodos de cálculo.
Vamos então calcular a similaridade entre os livros presentes no pacote:
# normalizar os livros pelo seu tamanho
corpus_dfm_norm <- dfm_weight(corpus_dfm, "relfreq")
corpus_simil <- textstat_simil(corpus_dfm_norm, method = "correlation",
margin = "documents", upper = TRUE,
diag = FALSE)
# ver os resultados individualmente para cada livro
round(corpus_simil, 3)## A escrava Isaura
## A escrava Isaura
## Memórias de um Sargento de Milícias 0.524
## Memórias Póstumas de Brás Cubas 0.625
## O Alienista 0.431
## O Ateneu 0.512
## Memórias de um Sargento de Milícias
## A escrava Isaura 0.524
## Memórias de um Sargento de Milícias
## Memórias Póstumas de Brás Cubas 0.642
## O Alienista 0.502
## O Ateneu 0.550
## Memórias Póstumas de Brás Cubas
## A escrava Isaura 0.625
## Memórias de um Sargento de Milícias 0.642
## Memórias Póstumas de Brás Cubas
## O Alienista 0.585
## O Ateneu 0.631
## O Alienista O Ateneu
## A escrava Isaura 0.431 0.512
## Memórias de um Sargento de Milícias 0.502 0.550
## Memórias Póstumas de Brás Cubas 0.585 0.631
## O Alienista 0.450
## O Ateneu 0.450Alguns resultados são bem interessantes. O Alienista é mais diferente de todos, tendo uma correlação superior a 0,51 apenas com o livro Memórias Póstumas de Brás Cubas, coincidentemente ou não ambos do mesmo autor. A maior correlação pertence aos livros Memórias Póstumas de Brás Cubas e Memórias de um Sargento de Milícias.
Passemos então para a análise da dissimilaridade ou distância entre os livros, com o auxílio de um dendograma:
corpus_dist <- textstat_dist(corpus_dfm_norm, method = "euclidean",
margin = "documents", upper = TRUE,
diag = FALSE)
# ver os resultados individualmente para cada livro
plot(hclust(corpus_dist))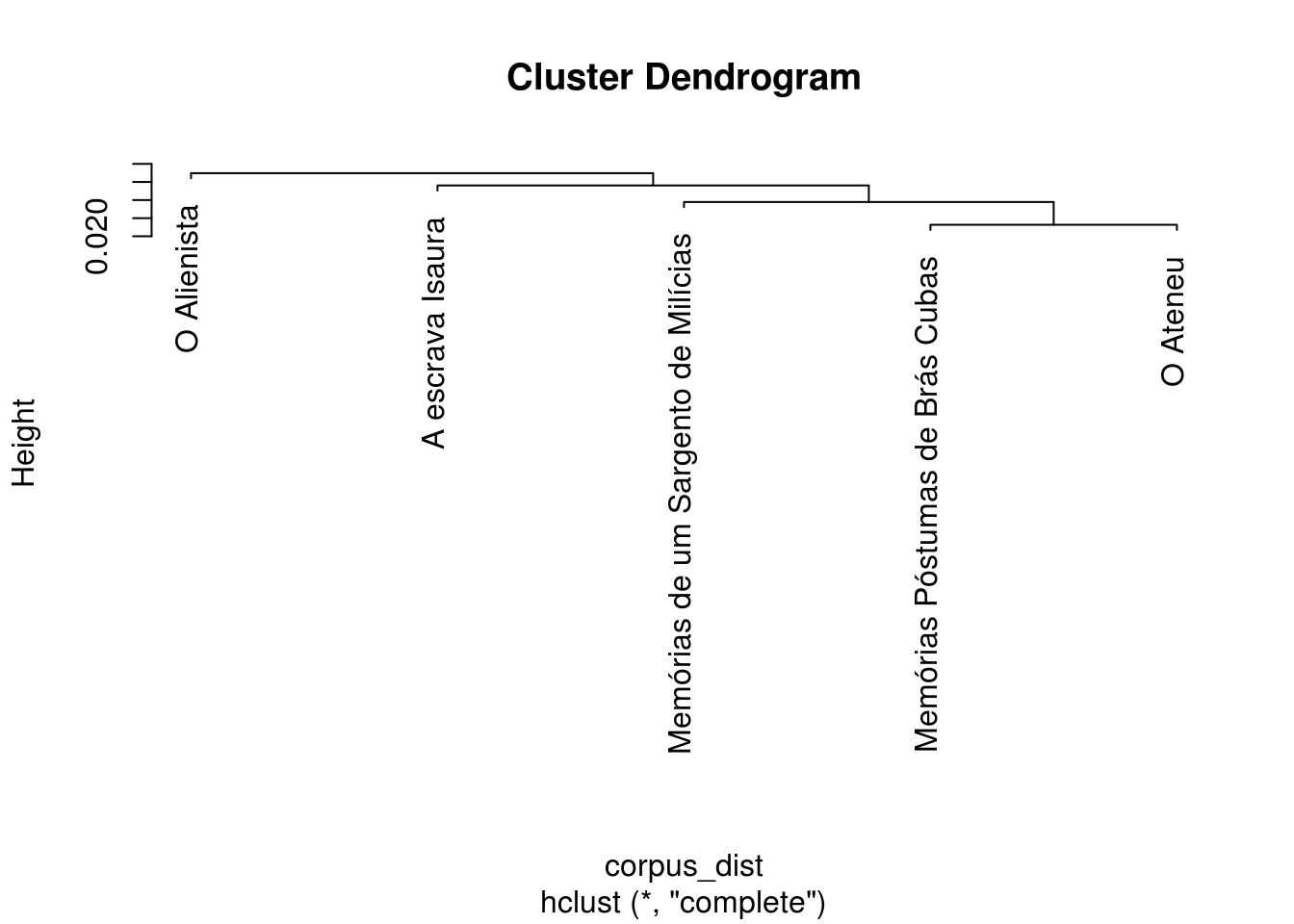
Análise de Sentimento
Como já publiquei no blog um post sobre Análise de Sentimento, não vou me alongar em repetir conceitos sobre o tema. Segue o código comentado:
# Criar um dataframe em que cada linha corresponda a uma unica palavra
df.token <- df %>%
unnest_tokens(term, text)
glimpse(df.token)## Observations: 252,299
## Variables: 5
## $ book_name <chr> "Memórias de um Sargento de Milícias", "Memór...
## $ chapter_name <chr> "Capítulo 1 - Origem, nascimento e batismo", ...
## $ url <chr> "https://pt.wikisource.org/wiki/Mem%C3%B3rias...
## $ paragraph_number <int> 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, ...
## $ term <chr> "era", "no", "tempo", "do", "rei", "uma", "da...# importar lexico de sentimentos
data("oplexicon_v3.0")
df.token <- df.token %>%
inner_join(oplexicon_v3.0, by = "term")Um pergunta muito interessante a se fazer é se o sentimento varia ao longo dos capítulos dos livros. Os livros ficam mais (ou menos) positivos a medida em que se aproximam do final?
Para isso, primeiro precisamos normalizar os livros, visto que eles apresentam tamanhos e quantidades de capítulos diferentes.
# extrair capitulos de cada livro
df_chapter_number <- df.token %>%
distinct(book_name, chapter_name) %>%
group_by(book_name) %>%
# normalizar capitulo de acordo com sua posicao no livro
mutate(chapter_number_norm = row_number()/max(row_number()))
glimpse(df_chapter_number)## Observations: 252
## Variables: 3
## $ book_name <chr> "Memórias de um Sargento de Milícias", "Me...
## $ chapter_name <chr> "Capítulo 1 - Origem, nascimento e batismo...
## $ chapter_number_norm <dbl> 0.02083333, 0.04166667, 0.06250000, 0.0833...Agora calculamos o sentimento de cada capítulo, que corresponde à soma da polaridade de suas palavras:
df.sentiment <- df.token %>%
# calcular sentimento por capitulo
group_by(book_name, chapter_name) %>%
summarise(polarity = sum(polarity, na.rm = TRUE)) %>%
ungroup() %>%
# retornar posicao relativa (ou normalizada) do capitulo de cada livro
left_join(df_chapter_number) %>%
arrange(book_name, chapter_number_norm)
# grafico
df.sentiment %>%
ggplot(aes(x = chapter_number_norm, y = polarity)) +
geom_line() +
facet_wrap(~ book_name, ncol = 5, labeller = label_wrap_gen(20)) +
labs(x = "Posição relativa no livro", y = "Sentimento") +
theme_bw()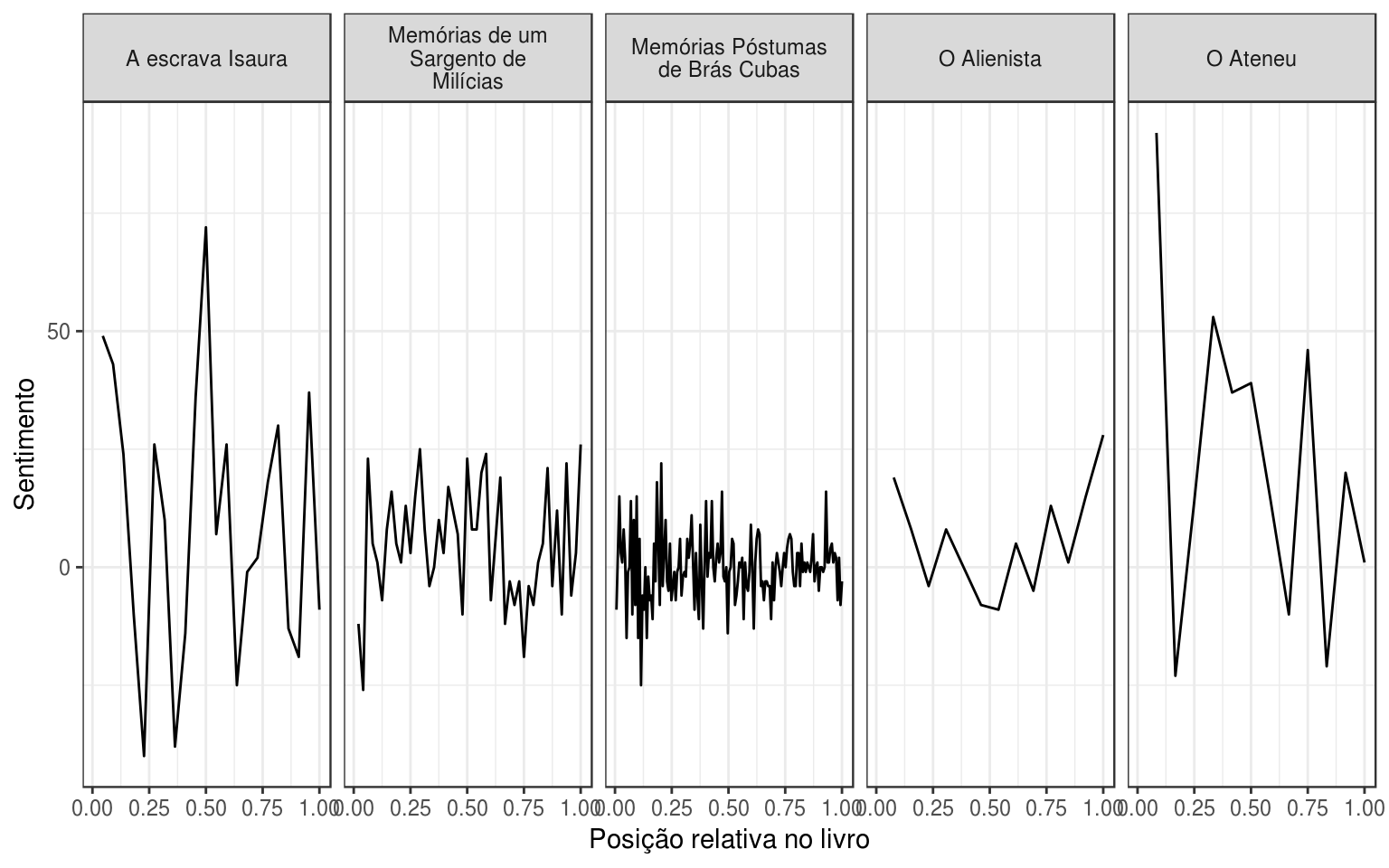
Os resultados são muito interessantes: De acordo com esse método, A Escrava Isaura e O Ateneu são verdadeiras montanhas-russas de emoções, enquanto que livros os “dois Memórias” são mais estáveis. O Alienista apresenta um sentimento que tem uma tendência decrescente até a metade e crescente após ela.
Complexidade léxica e ocorrência de palavras
A função textstat_lexdiv traz várias métricas de complexidade e diversidade léxicas. Novamente, recomendo a leitura de sua documentação para conhecer as métricas disponíveis.
# aplicando a funcao no objeto sem stopwords e pontuação
lexdiv <- textstat_lexdiv(corpus_dfm, measure = "TTR")
lexdiv## A escrava Isaura Memórias de um Sargento de Milícias
## 0.3062233 0.2517707
## Memórias Póstumas de Brás Cubas O Alienista
## 0.3139269 0.4291334
## O Ateneu
## 0.4134223#grafico
lexdiv %>%
as.data.frame() %>%
magrittr::set_colnames("TTR") %>%
tibble::rownames_to_column("livro") %>%
mutate(livro = forcats::fct_reorder(livro, TTR)) %>%
ggplot(aes(x = livro, y = TTR)) +
geom_col(fill = "cadetblue4") +
coord_flip() +
labs(x = NULL, y = "TTR") +
theme_minimal()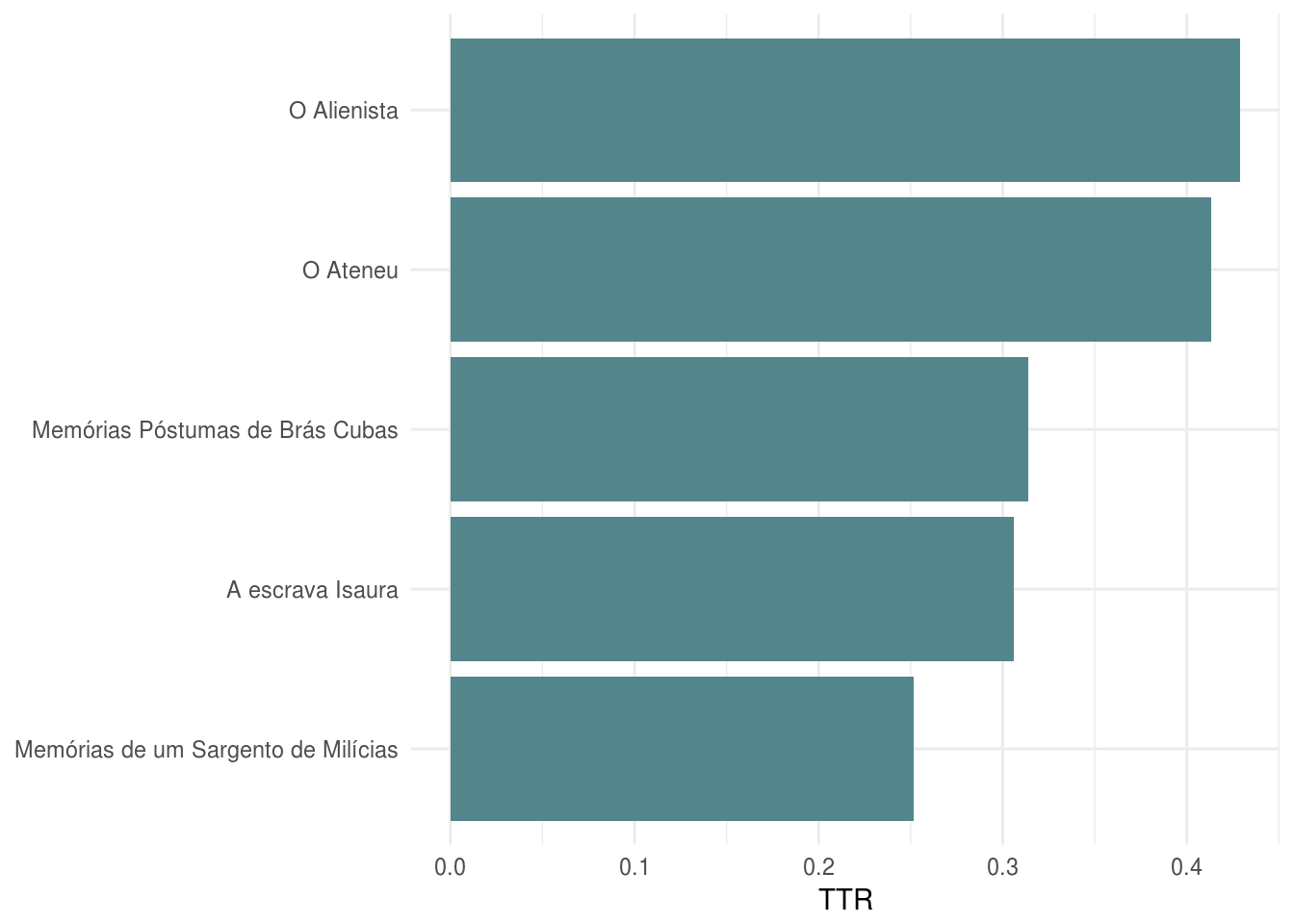
O livro que apresenta a maior diversidade léxica, de acordo com a métrica Type-Token Ratio (TTR), é O Alienista. Memórias de um Sargento de Milícias vem bem atrás dos demais.
De todas os gráficos que apresentei neste post, o mais legal vem a seguir. É possível plotar a ocorrência de uma determinada palavra ao longo dos livros analisados. Por exemplo, a ocorrência da palavra amor é uniformemente distribuída nos livros?
kwic(meu_corpus, "amor") %>% textplot_xray(scale = "relative")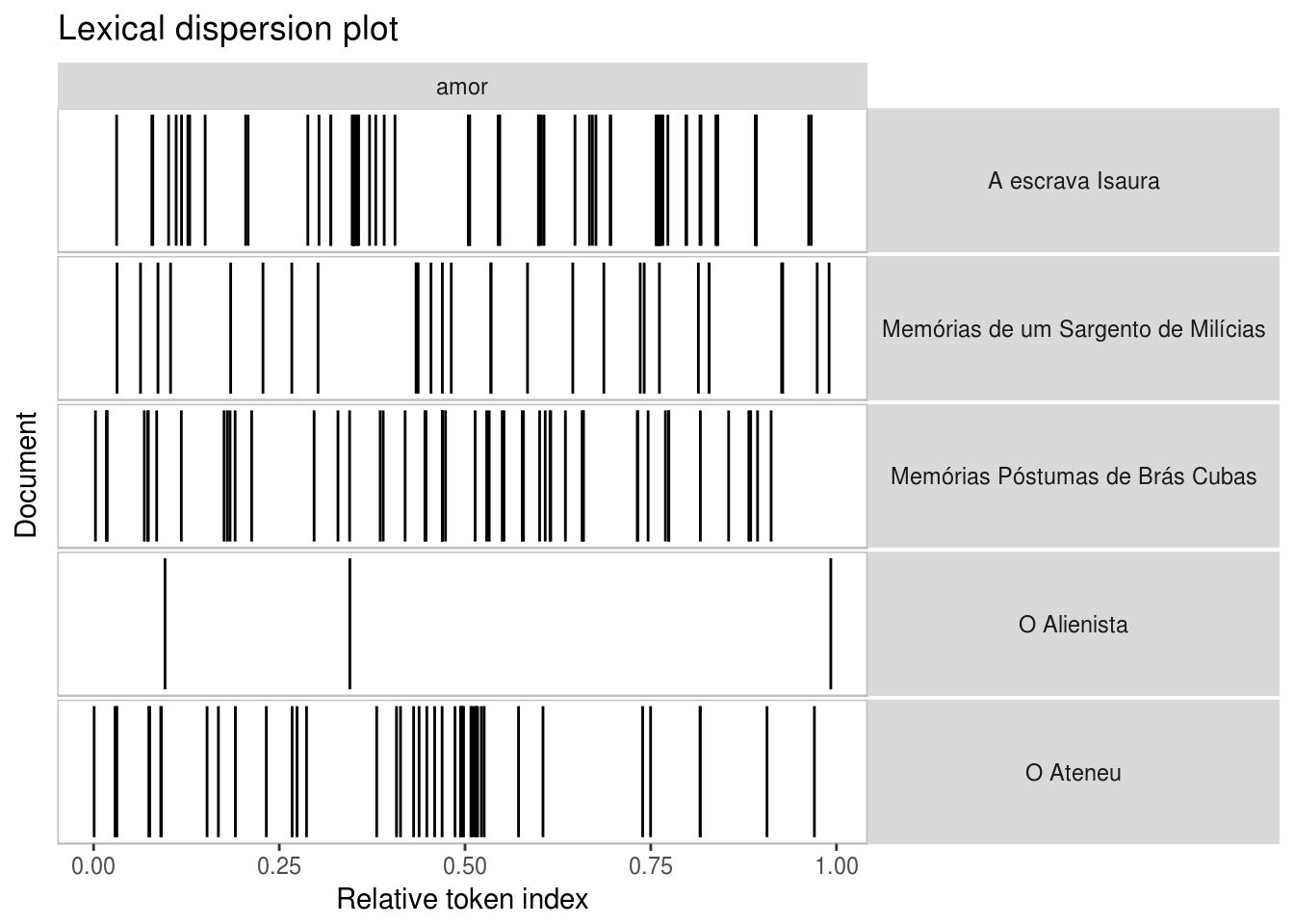
Com o gráfico acima, é possível ver que a palavra amor aparece, no livro Ateneu, muito mais frequentemente na primeira metade do que na segunda. Nos demais livros, a ocorrência da palavra é mais uniforme.
Outro exemplo interessante surge com a busca da palavra fogo. Quem já leu O Ateneu já consegue imaginar como serão os resultados:
kwic(meu_corpus, "fogo") %>% textplot_xray(scale = "relative")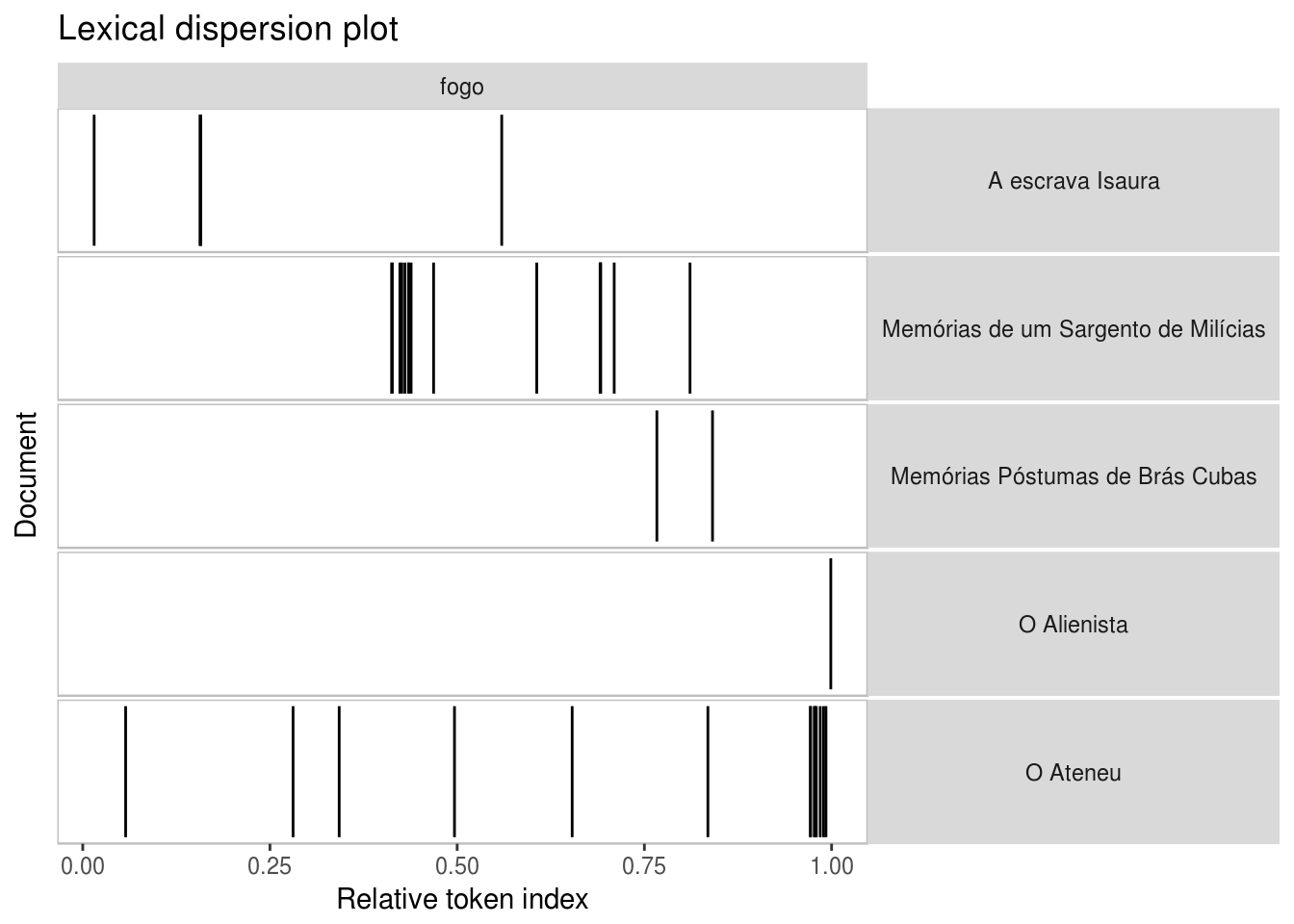
Conclusão
Eu realmente torço para que o literaturaBR e o lexiconPT atinjam seus potenciais e sejam dois grandes marcos em pesquisas em Text Mining com textos em português. Toda sugestão ou pedido de melhorias serão muitíssimos bem-vindos.