Pessoas adoram mapas. Sempre que puder fazer mapas para representar visualmente uma determinada informação, faça!
Suponha que você deseja fazer uma visualização da taxa de homicídio por estados brasileiros. Nada te impede de fazer um gráfico de barras, onde cada UF seria representado por uma barra cujo tamanho seria dependente do valor da taxa, mas teria um impacto visual menor em que cada estado estaria colorido de acordo com essa variável.
Contudo, em algumas situações, um mapa é a única maneira possível de transmitir com clareza uma ideia. Esta é a ideia deste post: mostrar como um mapa pode ser útil para mostrar a evolução das abertudas de escolas municipais na cidade de São Paulo.
Coleta e limpeza dos dados
Eu já tive a oportunidade de participar de uma palestra do pessoal da Secretaria Municipal de Educação de São Paulo, onde conheci suas iniciativas de dados abertos. Esses projetos são benéficos não só para a população como um todo, por toda a questão da transparência, mas especialmente para quem deseja desenvolver projetos para praticar análise de dados, ganhando assim experiência real para lidar com tarefas de limpeza, manuseio e visualização de dados.
O dataset de interesse deste post é o Cadastro de escolas municipais, conveniadas e privadas.
# pacotes
library(tidyverse)
library(ggmap)
library(gganimate)
library(lubridate)# definir locale para lidar com caracteres especiais
lcl <- locale(encoding = "ISO-8859-1")
df <- read_csv2("/home/sillas/R/Projetos/paixaopordados-blogdown/data/escolasr34dez2017.csv",
locale = lcl)
# dimensoes do dataset
dim(df)## [1] 6878 53O dataset possui 53 colunas, mas só precisamos de realmente 3: as colunas de coordenadas geográficas e a de data de fundação das escolas.
df <- df %>%
select(DATA = DT_CRIACAO, LAT = LATITUDE, LON = LONGITUDE)
knitr::kable(head(df))| DATA | LAT | LON |
|---|---|---|
| 13-jun-88 | -23553905 | -46398452 |
| 04-jul-88 | -23489728 | -46670198 |
| 05-jul-88 | -23478312 | -46427344 |
| 27-mai-88 | -23612237 | -46749888 |
| 22-jun-88 | -23486142 | -46733901 |
| 07-jun-88 | -23611929 | -46750176 |
O output acima revela a necessidade de alguns ajustes de limpeza: converter a coluna DATA para a classe Date e dividir as colunas de latitude e longitude por um milhão para obter os valores corretos.
A transformação da coluna DATA poderia ser feita por funções automáticas, como a strptime, mas isso dependeria de algumas configurações internas do seu sistema operacional. Por isso, eu uso uma solução mais manual:
converter_mes <- function(x){
nomes <- c("jan", "fev", "mar", "abr", "mai", "jun",
"jul", "ago", "set", "out", "nov", "dez")
numeros <- str_pad(1:12, width = 2, pad = "0")
x <- str_replace_all(x, nomes[1], numeros[1])
x <- str_replace_all(x, nomes[2], numeros[2])
x <- str_replace_all(x, nomes[3], numeros[3])
x <- str_replace_all(x, nomes[4], numeros[4])
x <- str_replace_all(x, nomes[5], numeros[5])
x <- str_replace_all(x, nomes[6], numeros[6])
x <- str_replace_all(x, nomes[7], numeros[7])
x <- str_replace_all(x, nomes[8], numeros[8])
x <- str_replace_all(x, nomes[9], numeros[9])
x <- str_replace_all(x, nomes[10], numeros[10])
x <- str_replace_all(x, nomes[11], numeros[11])
x <- str_replace_all(x, nomes[12], numeros[12])
x
}Escrita a função, passo para a transformação das colunas:
df <- df %>%
mutate(DATA_CLEAN = dmy(converter_mes(DATA)),
LAT = LAT/1e6,
LON = LON/1e6
) %>%
mutate(ANO = year(DATA_CLEAN)) %>%
# remover linhas onde LAT ou LON é NA
na.omit()
summary(df)## DATA LAT LON DATA_CLEAN
## Length:4576 Min. :-23.89 Min. :-47.05 Min. :1969-01-30
## Class :character 1st Qu.:-23.63 1st Qu.:-46.71 1st Qu.:2004-10-24
## Mode :character Median :-23.57 Median :-46.63 Median :2011-10-23
## Mean :-23.57 Mean :-46.60 Mean :2008-10-17
## 3rd Qu.:-23.51 3rd Qu.:-46.48 3rd Qu.:2015-05-08
## Max. :-22.89 Max. :-46.37 Max. :2068-12-12
## ANO
## Min. :1969
## 1st Qu.:2004
## Median :2011
## Mean :2008
## 3rd Qu.:2015
## Max. :2068Surgiu um novo erro: a coluna ANO possui valores acima do ano atual (2018). Isso provavelmente foi causado na conversão de datas como 30/08/68, que o R retornou 2068 ao invés de 1968. Sinceramente, não parei para investigar o motivo disso, até porque é facilmente consertado:
df <- df %>%
mutate(ANO = if_else(ANO > year(today()), ANO - 100, ANO))Apresentação dos dados
Primeiramente, qual a distribuição da abertura de novas escolas por ano?
df %>%
count(ANO) %>%
ggplot(aes(x = ANO, y = n)) +
geom_col(fill = "darkorange1") +
theme_minimal() +
labs(x = NULL, y = NULL,
title = "Quantidade de escolas fundadas por ano em São Paulo") +
scale_x_continuous(breaks = scales::pretty_breaks(n = 10))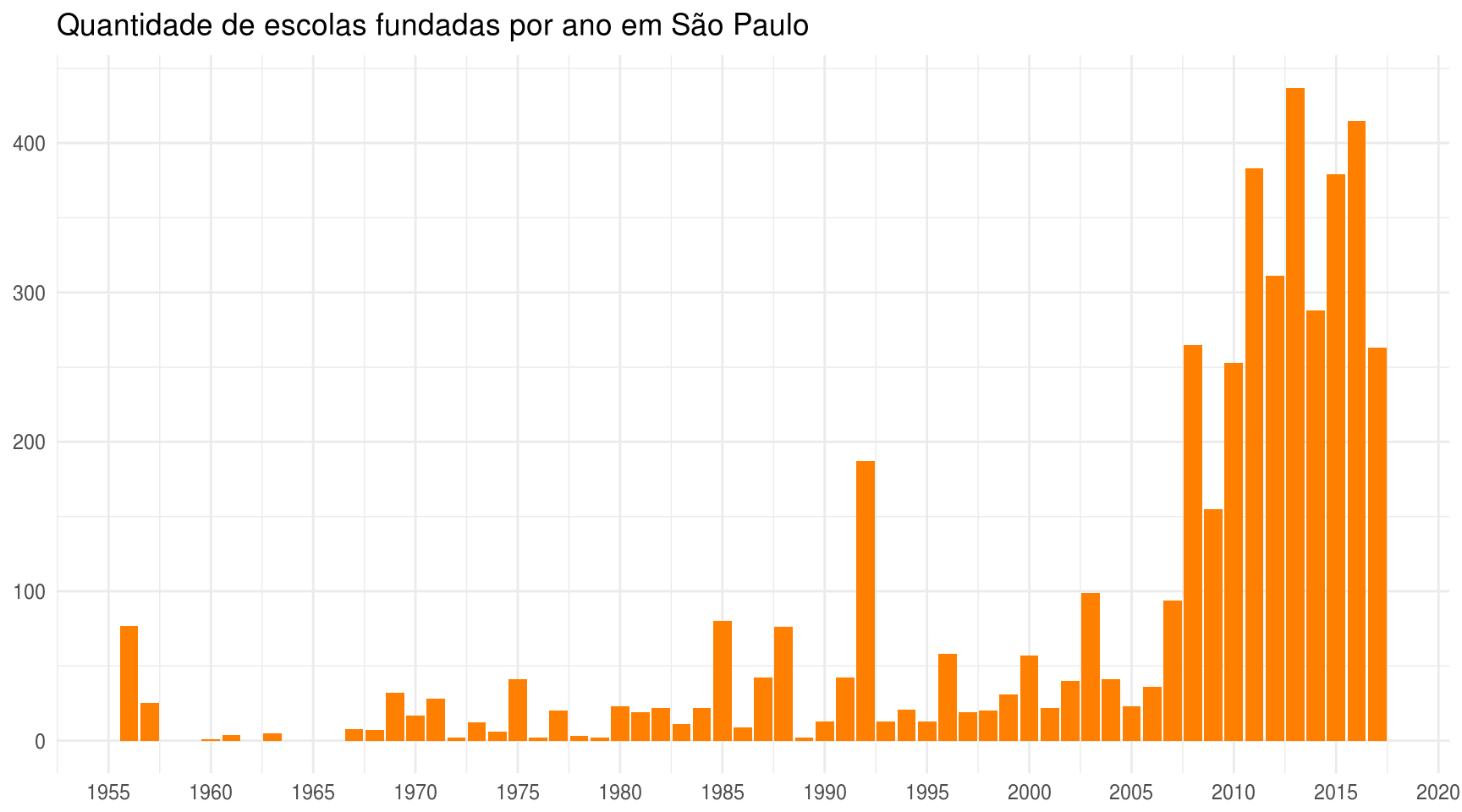
A grande maioria das escolas foi criada a partir do ano de 2005. Confesso que esperava uma distribuição mais uniforme.
Criando o mapa
Existem diversas maneiras de criar um mapa no R. O melhor método depende basicamente do tipo de dados que se tem em mãos. Caso seja necessário, por exemplo, plotar polígonos, áreas e fronteiras, o indicado é o combo do pacote sf e da função ggplot2::geom_sf. No nosso caso, como estamos interessados em plotar pontos e já possuímos os dados das coordenadas geográficas, uma das melhores opções é usar o pacote ggmap.
Para criar um mapa, são necessários dois parâmetros iniciais: um ponto central e um nível de zoom, que define a escala do gráfico.
# para o centro de sp, usei as coordenadas da praca da se, que peguei no google maps
praca_se <- c(lon = -46.634123, lat = -23.548408)
# o zoom é calculado pela funcao calc_zoom do ggmap
zoom_sp <- calc_zoom(lon = LON, lat = LAT, data = df)Apenas com esses dois parâmetros, já é possível plotar um mapa base:
mapa_sp <- get_map(location = praca_se,
zoom = zoom_sp,
maptype = "toner-lite")
ggmap(mapa_sp) +
# plotar praça da sé
geom_point(x = praca_se[1], y = praca_se[2], color = "red")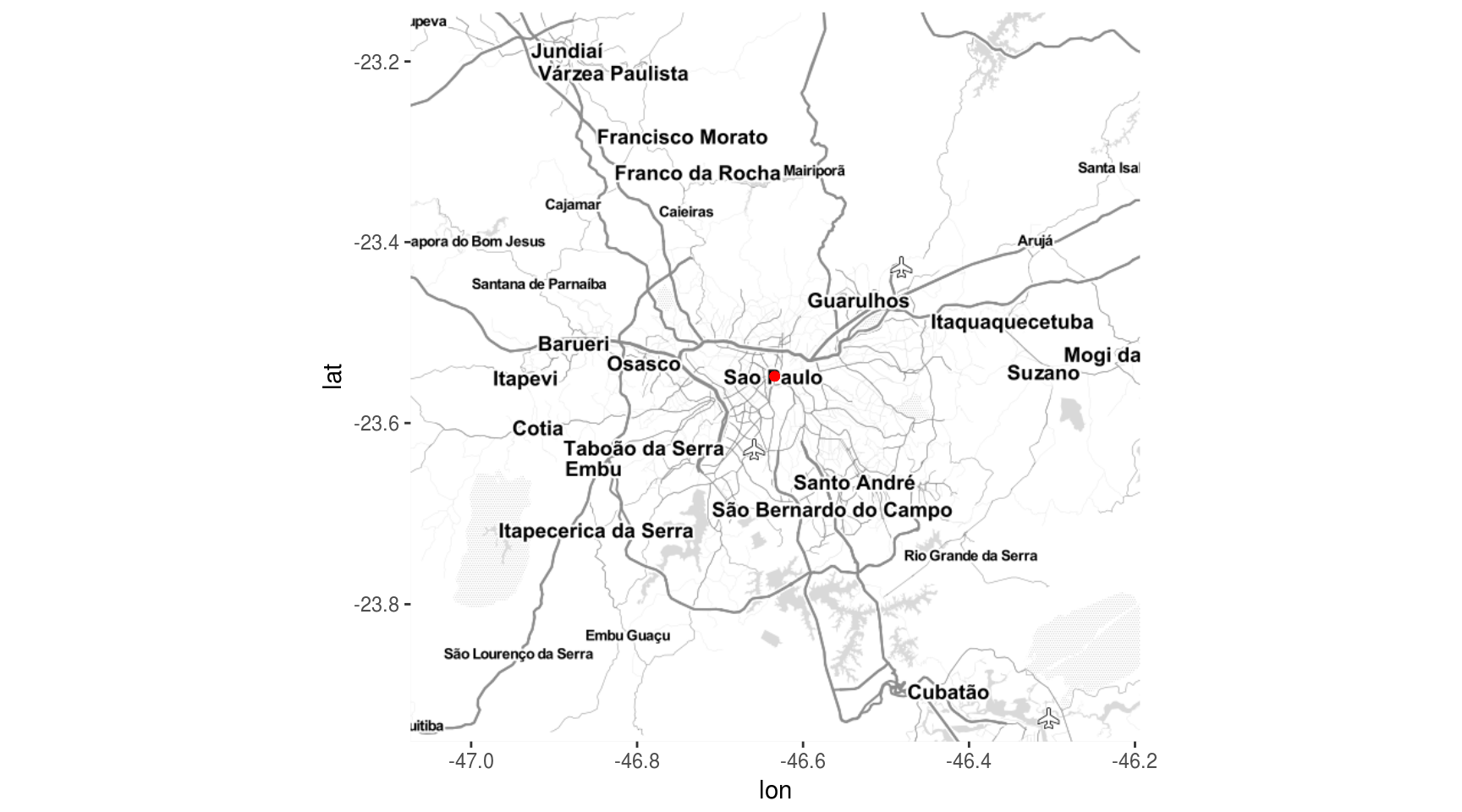
Vamos então adicionar um pouco de vida ao gráfico e plotar todas as escolas presentes no dataset:
ggmap(mapa_sp) +
geom_point(data = df, aes(x = LON, y = LAT),
color = "red", alpha = 0.1)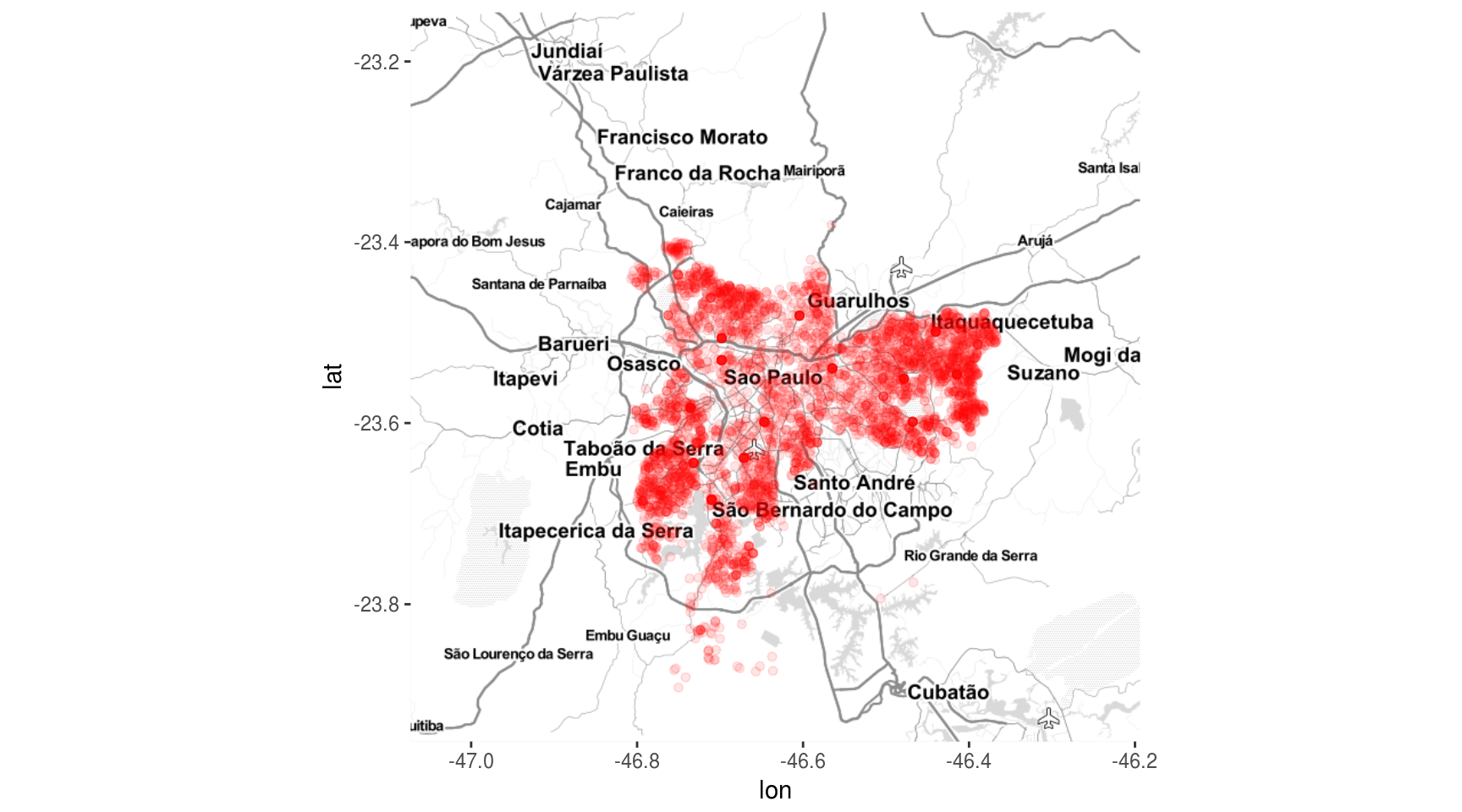
Aparantemente existe uma concentração de escolas perto, entre outras, da área de Itaquaquecetuba. Uma maneira de visualizar densidade de pontos é por meio do geom_density2d:
ggmap(mapa_sp) +
geom_density2d(data = df, aes(x = LON, y = LAT),
color = "red")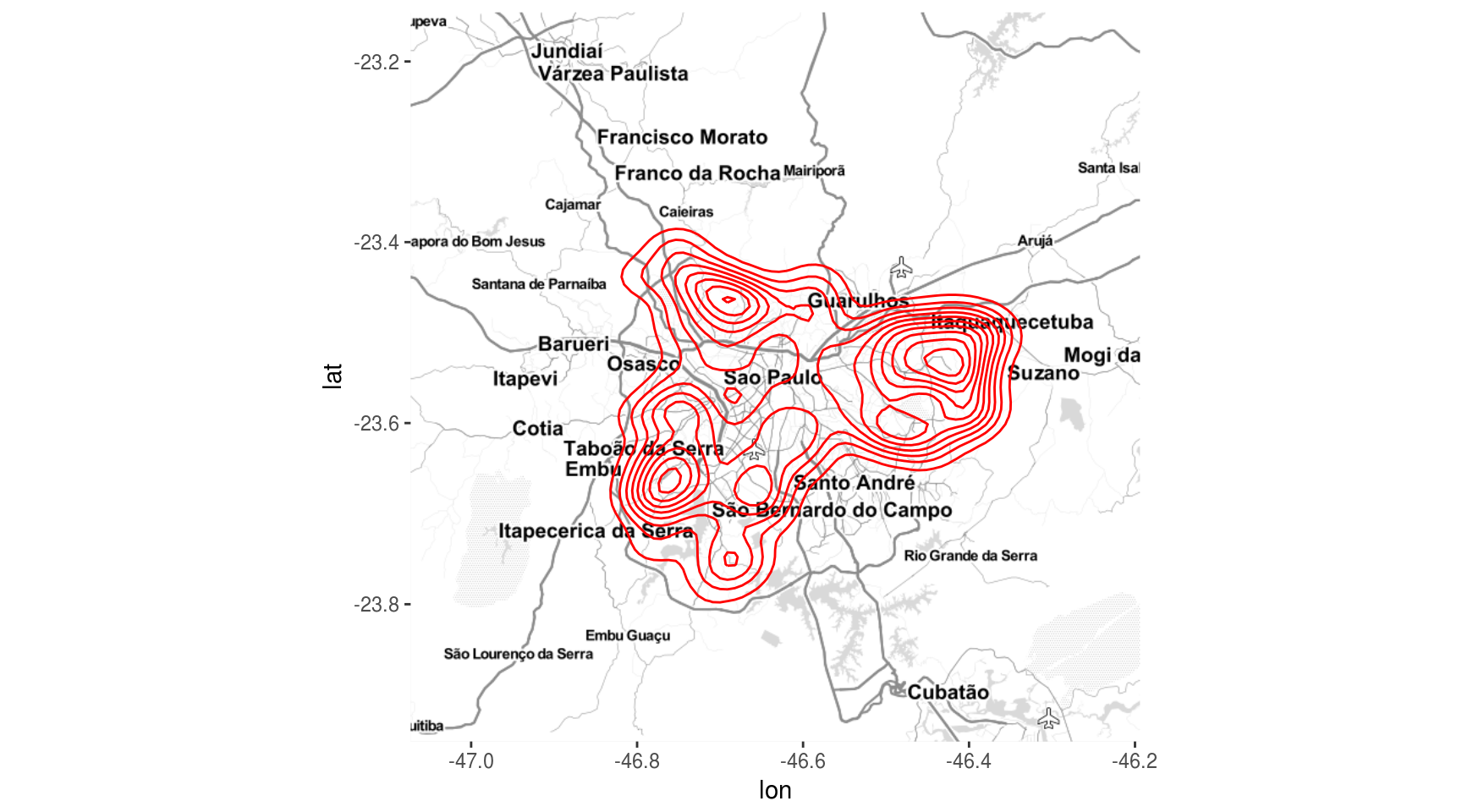
Acrescentando o elemento tempo no mapa
Ainda não mostrei como representar o fator tempo na visualização. Penso que isto pode ser feito de três maneiras: colorir as escolas de acordo com o ano de fundação, separar o gráfico em facets por ano ou, minha preferida, criar um gif composto por uma série de gráficos sobrepostos. Fazer isso é muito fácil com o auxílio do pacote gganimate:
Para criar uma sobreposição de gráficos ggplot com o pacote gganimate, basta setar a aesthetic especial frame com o nome da variável que você deseja usar para separar os gráficos em unidades individuais. O argumento cumulative é usado para que as escolas de anos mais recentes permaneçam no gráfico ao longo dos anos:
p <- ggmap(mapa_sp) +
geom_point(data = df,
aes(x = LON, y = LAT, frame = ANO,
cumulative = TRUE), color = "red", alpha = 0.1) +
labs(x = NULL, y = NULL, title = "Escolas em São Paulo em ")
# o argumento interval define o intervalo de transição do gif em segundos
gganimate(p = p, interval = .075)Taí! Com o auxílio do gráfico, é possível perceber (pelo menos foi o que vi, vai que é uma miragem) que, de acordo com o dataset, nas primeiras décadas foram priorizadas as áreas mais periféricas de São Paulo. A região mais central aparenta ter recebido mais escolas apenas a partir das últimas duas décadas.
Publicidade
Sou um dos intrutores do curso de Ciência de Dados do IBPAD. Temos um dia do curso voltado exclusivamente para visualização de dados, dentre eles mapas! Mais informações de novas turmas neste link.