No post anterior, mostramos como obter os dados de apartamentos para aluguel no Rio de Janeiro do site do OLX. Neste post, vamos analisar esses dados e ver se descobrimos algo interessante. Algumas das perguntas que podemos responder com os dados que temos são:
- Quais as principais diferenças entre os apartamentos nas cidades do Rio de Janeiro e Niterói?
- Quantos quartos os apartamentos têm em média?
- Quais os bairros com os aluguéis mais caros?
- A oferta de apartamentos de um bairro influencia o preço médio do aluguel?
- Existe relação entre o preço do aluguel de um imóvel e outras variáveis, como a taxa de condomínio?
Ressalto que no post anterior eu mostrei como obter dados de uma amostra de 50 apartamentos (os da primeira página). Aqui, eu estou usando os dados de todos os apartamentos (mais de 10000) do site do OLX que eu não posso disponibilizar por motivos legais (já que eles pertencem ao OLX, que é uma empresa privada).
library(magrittr) # não vivo sem esse pacote
library(tidyr) # data cleaning
library(dplyr) # data cleaning
library(ggplot2) # graficos
library(RColorBrewer)
library(stringr)
library(plotly)
azul = "#01a2d9" # definir cor para usar nos gráficos
devtools::source_gist("ae62d57836c37ebff4a5f7a8dc32eeb7", filename = "meu_tema.R") # carregar meu tema personalizado para gráficos no ggplot2load("/home/sillas/R/Projetos/olx/data/post2-df_apt.rdata")
df$bairro %<>% str_trim()Análise geral
Valor do aluguel
A melhor forma de mostrar a distribuição do preço do aluguel dos apartamentos no Rio de Janeiro é por meio de um histograma:
ggplot(df, aes(preco)) +
geom_histogram(binwidth = 1000, fill = azul) +
meu_tema() +
labs(x = "Aluguel (R$)", y = "Quantidade de apartamentos")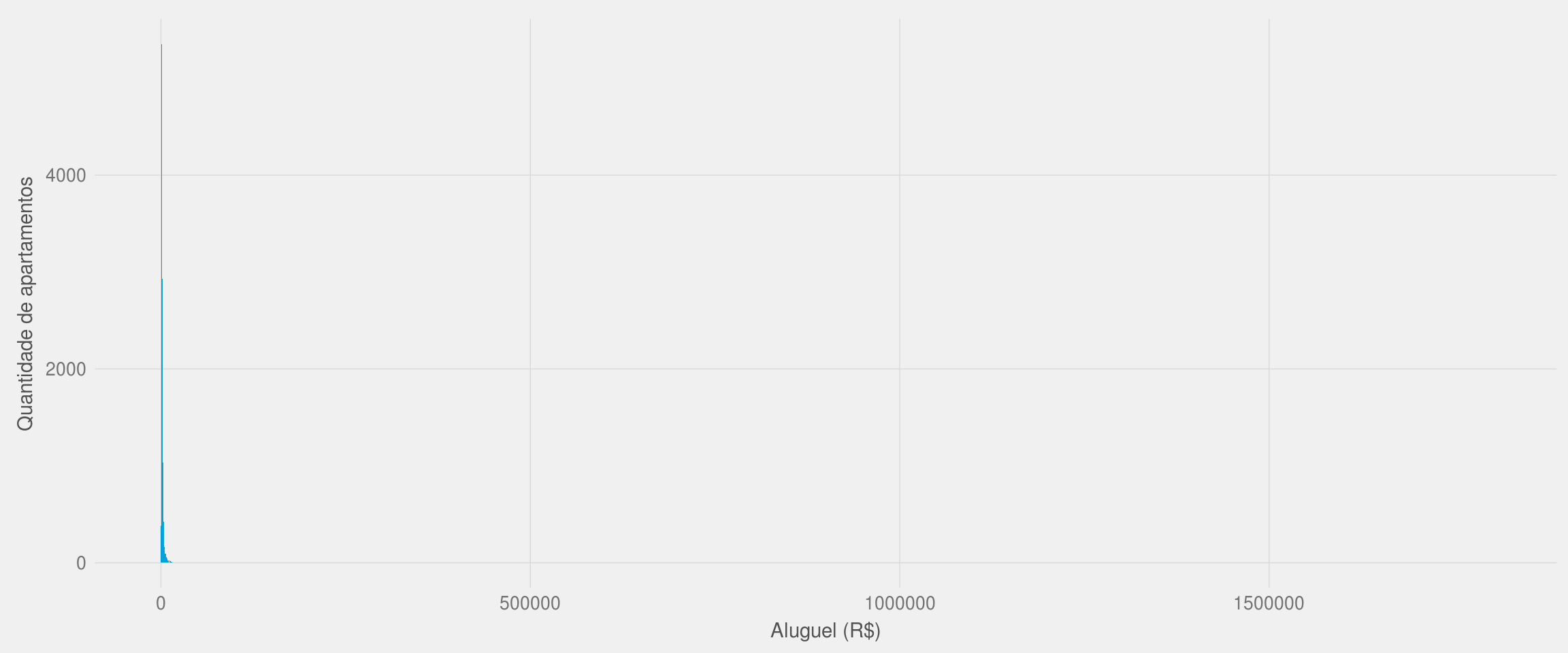
O histograma acima ficou muito distorcido devido à presença de alguns imóveis cujo valor do aluguel chega a mais de R$1.500.000. É necessário, portanto, remover as anomalias do dataset. Como existem apenas 34 imóveis (menos de 1% do total) cujo aluguel é superior a R$20000, decidi usar esse valor como limite máximo para a remoção de anomalias.
df2 <- df %>% filter(preco <= 20000)
ggplot(df2, aes(preco)) +
geom_histogram(breaks = seq(0, 20000, 500), fill = azul) +
meu_tema() +
scale_x_continuous(breaks = seq(0, 20000, 1000)) +
labs(x = "Aluguel (R$)", y = "Quantidade de apartamentos")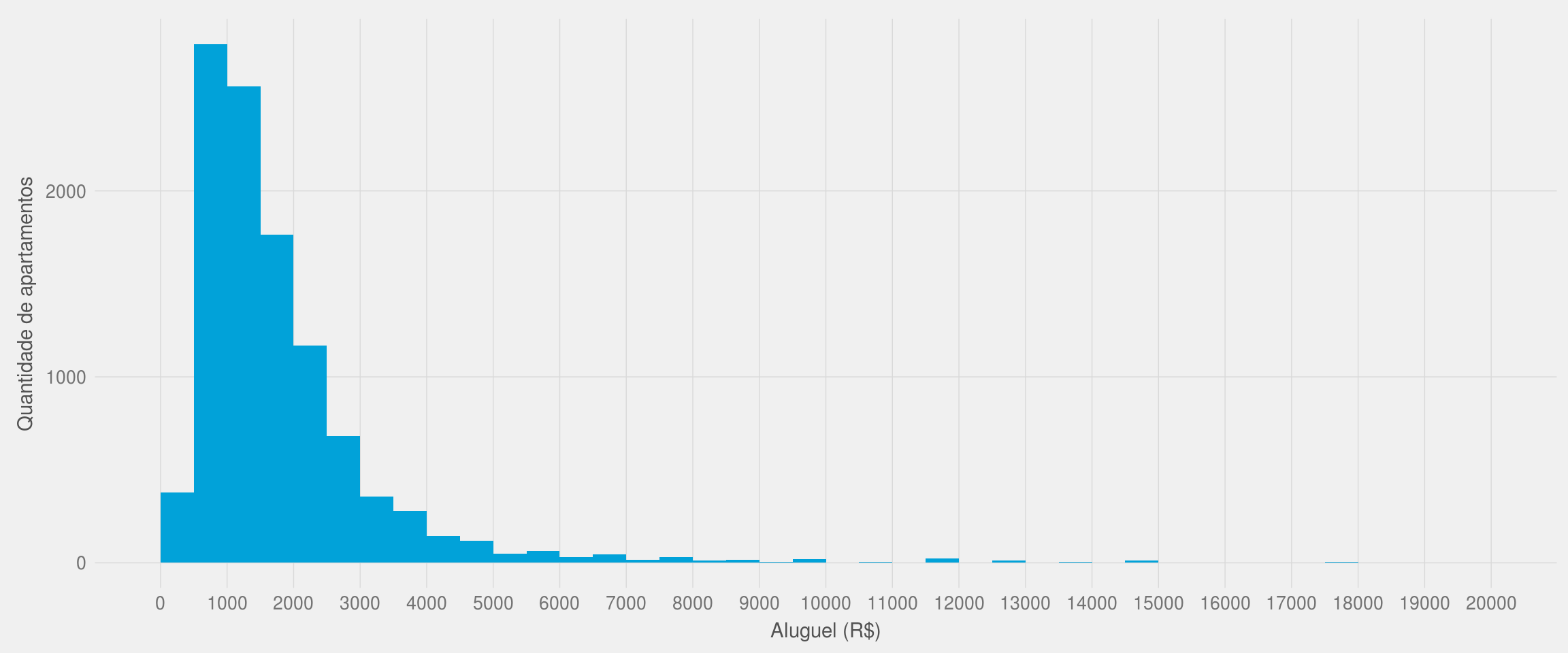
O histograma acima mostra que a maior parte dos apartamentos está no intervalo entre R$500,01 a R$1000,00. Contudo, aumentar o número de intervalos do histograma pode nos ajudar a encontrar conclusões ainda melhores. Veja o que encontramos ao reduzir a “espessura” de cada bloco do histograma de 500 para 100:
ggplot(df2, aes(preco)) +
geom_histogram(breaks = seq(0, 20000, 100), fill = azul) +
meu_tema() +
coord_cartesian(xlim = c(0, 5000)) +
scale_x_continuous(breaks = seq(0, 20000, 500)) +
labs(x = "Aluguel (R$)", y = "Quantidade de apartamentos")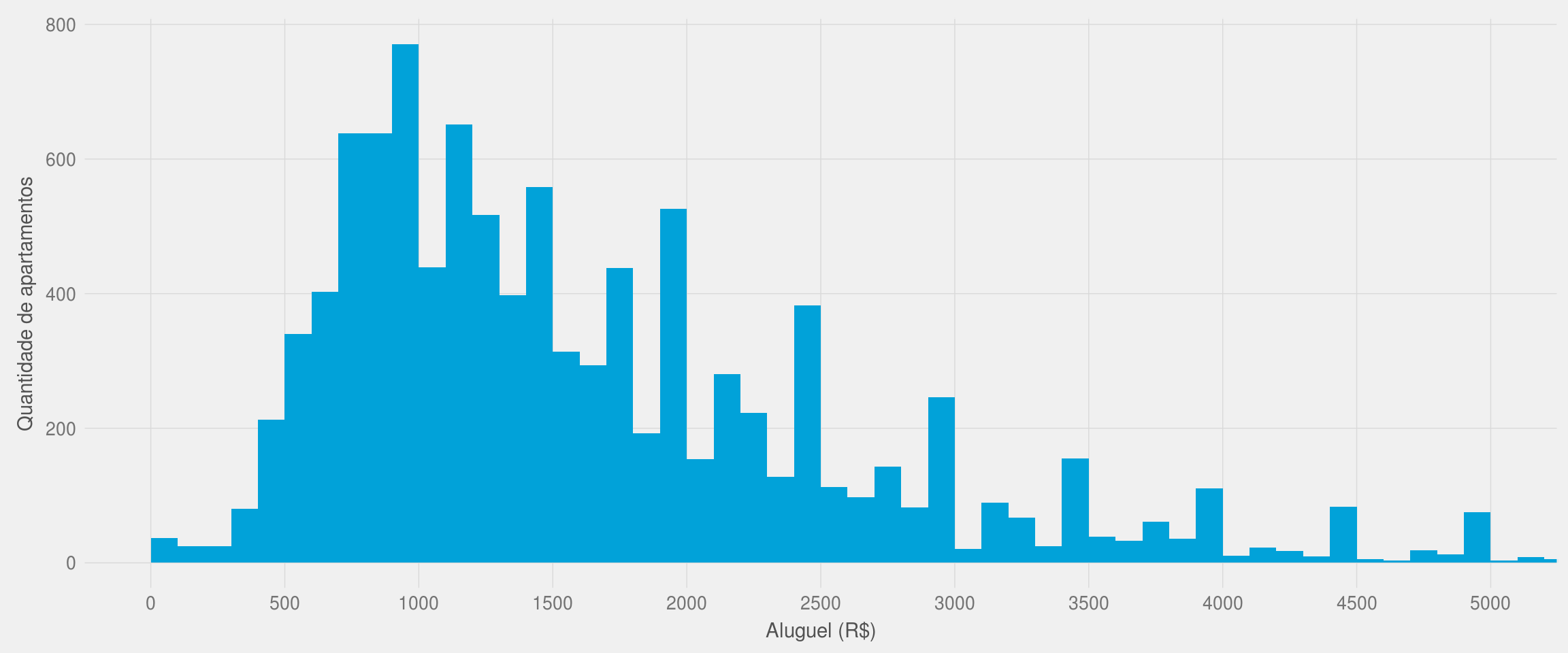
Uma possível conclusão do gráfico acima é que os locadores tendem a precificar seus apartamentos em um valor “fechado” a cada R$500,00, como R$500, R$1000, R$1500, etc. Além disso, o fato de existirem mais apartamentos à esquerda de cada “pico” ao invés de à direita mostra que os proprietários preferem “arredondar” os valores para cima, nunca para baixo. Em outras palavras: a decisão sobre o preço do aluguel de um apartamento é enviesada e não segue uma lógica racional. Novamente, isso é apenas uma conclusão pessoal minha.
Para ser mais preciso, confira a quantidade numérica de apartamentos agrupados em intervalos de preço de aluguel de R$100:
df2 %>% filter(between(preco, 1900, 3100)) %>% count(cut_interval(preco, length = 100, dig.lab = 5))## # A tibble: 12 x 2
## `cut_interval(preco, length = 100, dig.lab = 5)` n
## <fctr> <int>
## 1 [1900,2000] 679
## 2 (2000,2100] 154
## 3 (2100,2200] 280
## 4 (2200,2300] 223
## 5 (2300,2400] 128
## 6 (2400,2500] 383
## 7 (2500,2600] 113
## 8 (2600,2700] 97
## 9 (2700,2800] 143
## 10 (2800,2900] 82
## 11 (2900,3000] 246
## 12 (3000,3100] 21Temos, por exemplo, que existe um brusco aumento na quantidade de apartamentos no intervalo entre R$2301 a R$2400 e R$2401 a R$2500 e uma brusca redução entre este último intervalo e o seguinte (R$2501 a R$2600.)
Área do condomínio
De forma semelhante ao preço do aluguel, vamos analisar a distribuição das áreas dos condomínios por meio de um histograma.
ggplot(df2, aes(x = area_condominio)) +
geom_histogram(fill = azul) +
meu_tema() +
labs(x = "Área do condomínio (m²)", y = NULL)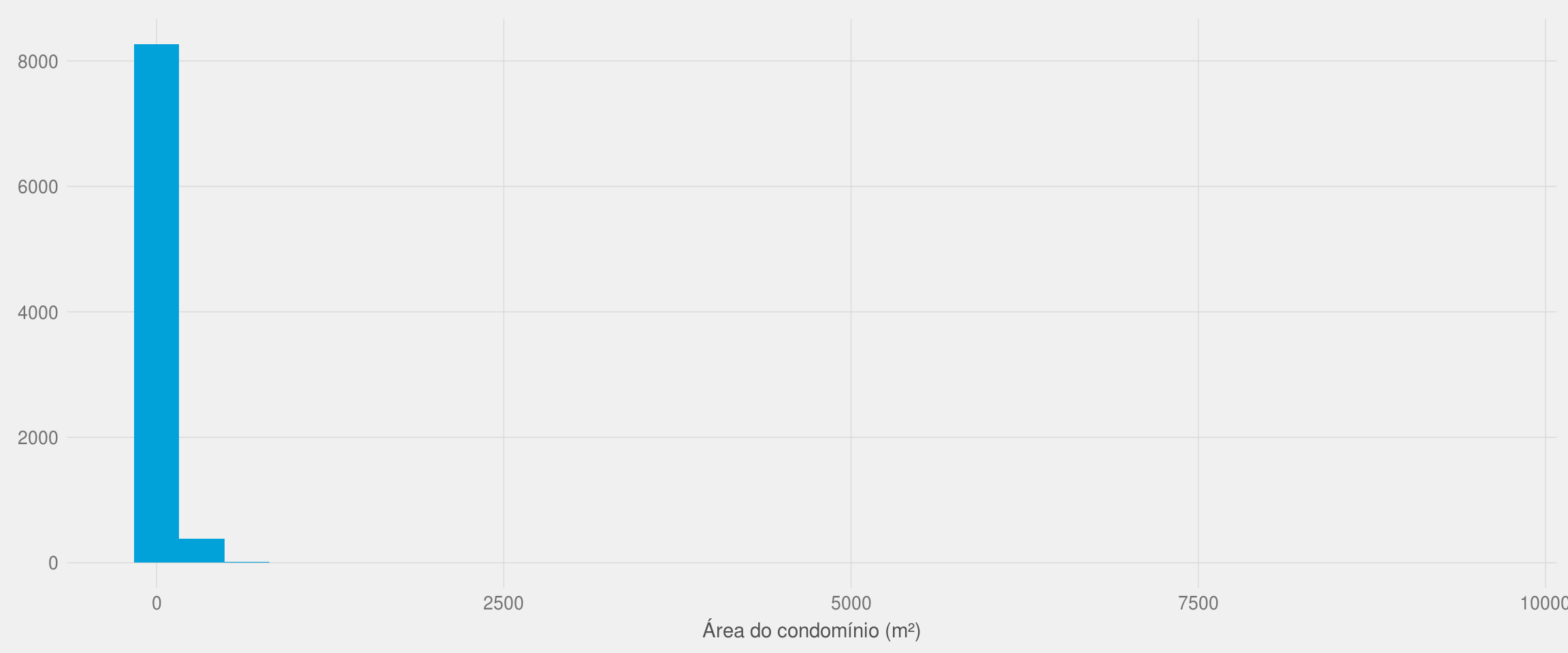
df2 %>% filter(area_condominio > 7000)## link
## 1 http://rj.olx.com.br/rio-de-janeiro-e-regiao/imoveis/alugo-apartamento-campo-grande-254728943
## 2 http://rj.olx.com.br/rio-de-janeiro-e-regiao/imoveis/locacao-tijuca-209451015
## titulo preco cidade bairro
## 1 Alugo Apartamento- Campo Grande 850 Rio de Janeiro Campo Grande
## 2 Locação Tijuca 3800 Rio de Janeiro Maracanã
## adicional tem_quarto tem_area
## 1 2 quarto | 57150 m² | Condomínio: RS 100 TRUE TRUE
## 2 3 quarto | 9438 m² | Condomínio: RS 0000 | 1 vaga TRUE TRUE
## tem_taxa tem_garagem qtd_quarto taxa_condominio area_condominio cep
## 1 TRUE FALSE 2 100 7150 23080300
## 2 TRUE TRUE 3 0 9438 20271063
## garagem
## 1 NA
## 2 1Novamente, o gráfico foi distorcido devido à presença de anomalias. Existe até apartamento cuja área informada é de mais de 57 mil m²! Precisamos, novamente, remover essas anomalias dos nossos dados, mas qual seria um bom valor para o limite máximo da área? Podemos responder a essa pergunta analisando os percentis:
quantile(df2$area_condominio, seq(0, 1, 0.01), na.rm = TRUE)## 0% 1% 2% 3% 4% 5% 6% 7% 8%
## 1.00 18.00 22.00 25.00 26.36 29.00 30.00 30.00 31.00
## 9% 10% 11% 12% 13% 14% 15% 16% 17%
## 34.00 35.00 36.00 40.00 40.00 40.00 40.00 42.00 44.00
## 18% 19% 20% 21% 22% 23% 24% 25% 26%
## 45.00 45.00 46.80 48.00 49.00 50.00 50.00 50.00 50.00
## 27% 28% 29% 30% 31% 32% 33% 34% 35%
## 50.00 50.00 52.00 53.00 55.00 55.00 55.00 56.00 57.00
## 36% 37% 38% 39% 40% 41% 42% 43% 44%
## 58.00 60.00 60.00 60.00 60.00 60.00 60.00 61.00 63.00
## 45% 46% 47% 48% 49% 50% 51% 52% 53%
## 64.00 65.00 65.00 65.00 66.00 68.00 68.00 70.00 70.00
## 54% 55% 56% 57% 58% 59% 60% 61% 62%
## 70.00 70.00 70.00 70.00 70.00 72.00 73.00 74.24 75.00
## 63% 64% 65% 66% 67% 68% 69% 70% 71%
## 75.00 76.00 78.00 79.00 80.00 80.00 80.00 80.00 80.64
## 72% 73% 74% 75% 76% 77% 78% 79% 80%
## 83.00 85.00 85.00 88.00 90.00 90.00 90.00 90.00 94.00
## 81% 82% 83% 84% 85% 86% 87% 88% 89%
## 96.00 98.00 100.00 100.00 104.00 110.00 110.00 113.00 120.00
## 90% 91% 92% 93% 94% 95% 96% 97% 98%
## 120.00 126.00 130.00 140.00 150.00 160.00 179.00 200.00 230.00
## 99% 100%
## 300.00 9438.00Vemos que apenas 1% dos apartamentos possui área informada superior a 300m². Portanto, esse será o nosso valor máximo para definir as anomalias.
df2 %<>% filter(area_condominio <= 300)
ggplot(df2, aes(x = area_condominio)) +
geom_histogram(breaks = seq(0, 300, 10), fill = azul) +
meu_tema() +
labs(x = "Área do condomínio (m²)", y = NULL) +
scale_x_continuous(breaks = seq(0, 300, 50))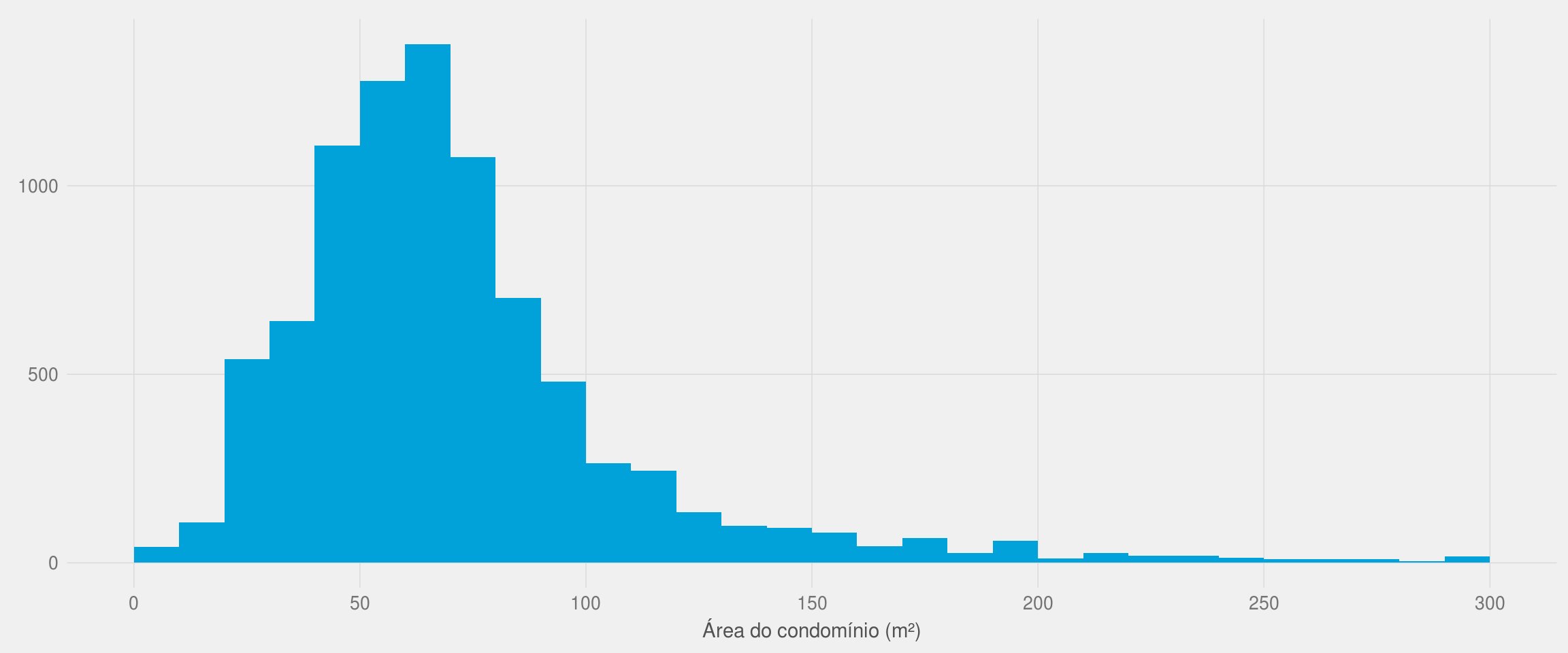
A maior parte dos condomínios têm área entre 41 a 70m².
Taxa do condomínio
De forma semelhante ao preço do aluguel, vamos analisar a distribuição das áreas dos condomínios por meio de um histograma.
limite <- max(df2$taxa_condominio, na.rm = TRUE)
ggplot(df2, aes(x = taxa_condominio)) +
geom_histogram(breaks = seq(0, limite, 100), fill = azul) +
meu_tema() +
labs(x = "Taxa do condomínio (R$)", y = NULL) +
scale_x_continuous(breaks = seq(0, limite, 500))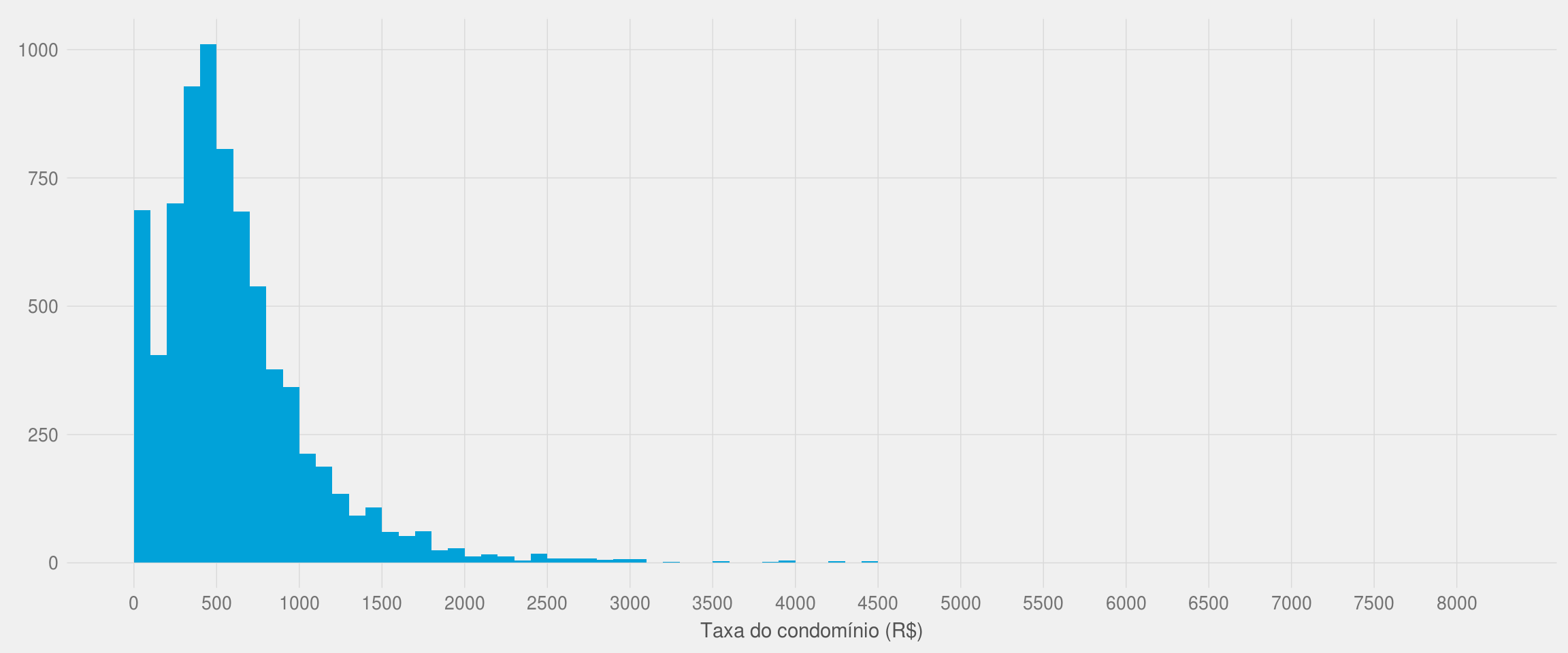
# Reduzindo o comprimento dos intervalos
ggplot(df2, aes(x = taxa_condominio)) +
geom_histogram(breaks = seq(0, limite, 50), fill = azul) +
meu_tema() +
labs(x = "Taxa do condomínio (R$)", y = NULL) +
scale_x_continuous(breaks = seq(0, limite, 500))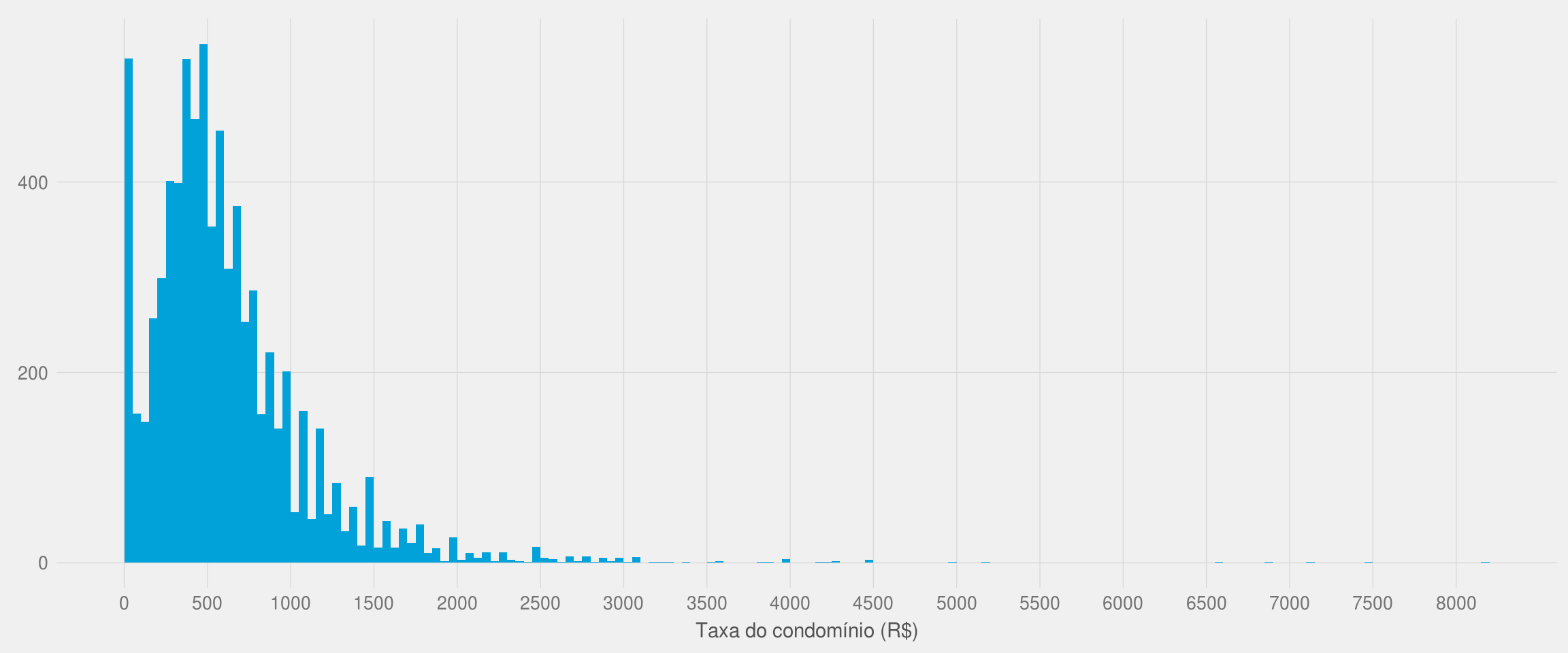
Nota-se que a taxa de condomínio apresenta o mesmo comportamento que o preço do aluguel.
Quartos
Quantos quartos têm em média os apartamentos?
ggplot(df, aes(x = qtd_quarto)) +
geom_bar(fill = azul) +
meu_tema() +
labs(x = "Quartos", y = "Quantidade de apartamentos")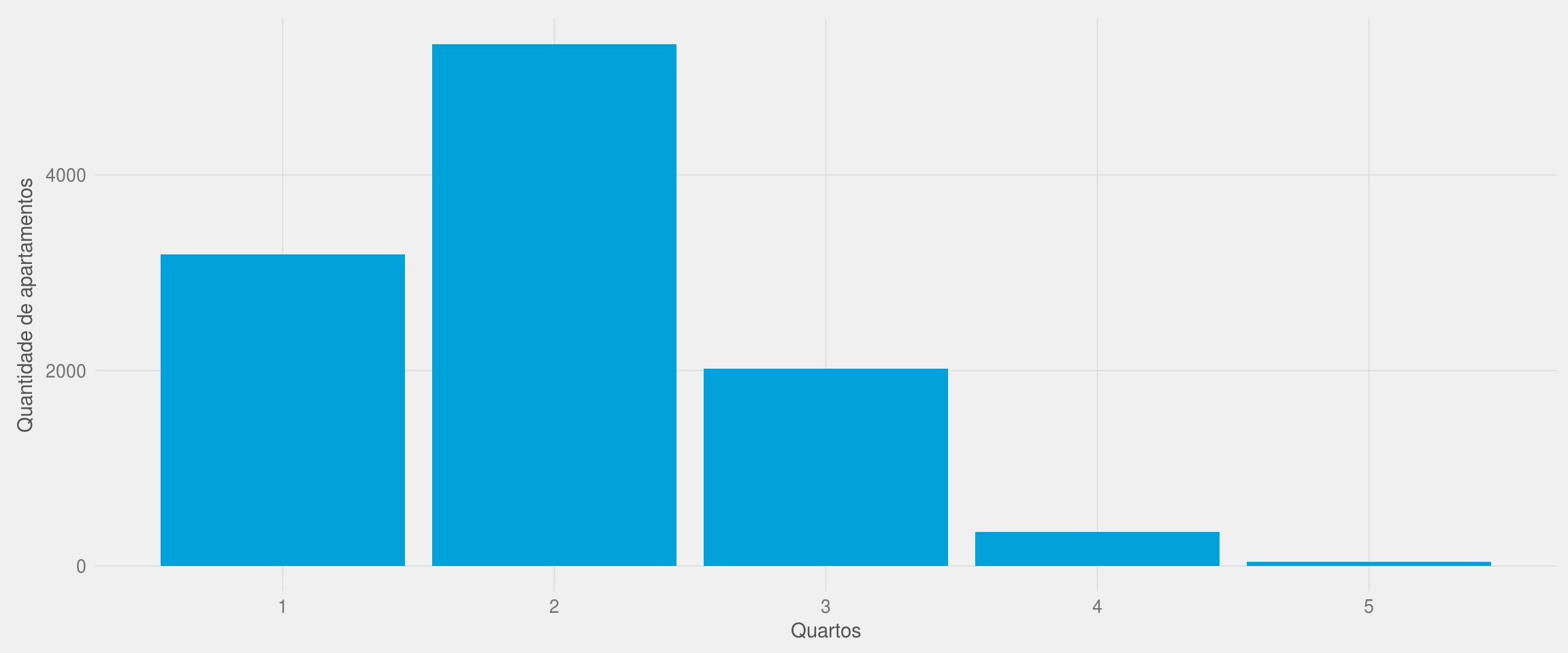
Análise Rio de Janeiro x Niterói
Agora, vamos analisar como diferentes variáveis diferem de acordo com a cidade. Primeiramente, quantos bairros diferentes temos no dataset?
df %>%
group_by(cidade) %>%
summarise(qtd_bairros = n_distinct(bairro),
qtd_apartamentos = n())## # A tibble: 2 x 3
## cidade qtd_bairros qtd_apartamentos
## <chr> <int> <int>
## 1 Niterói 39 1276
## 2 Rio de Janeiro 154 9804Temos mais de 154 bairros no Rio de Janeiro, o que mostra que o OLX cobre praticamente toda a cidade.
Aluguel
Espera-se que a diferença do aluguel seja diferente para as duas cidades, correto?
ggplot(df2, aes(x = cidade, y = preco)) +
geom_boxplot() +
meu_tema() +
labs(x = NULL, y = "Aluguel (R$)")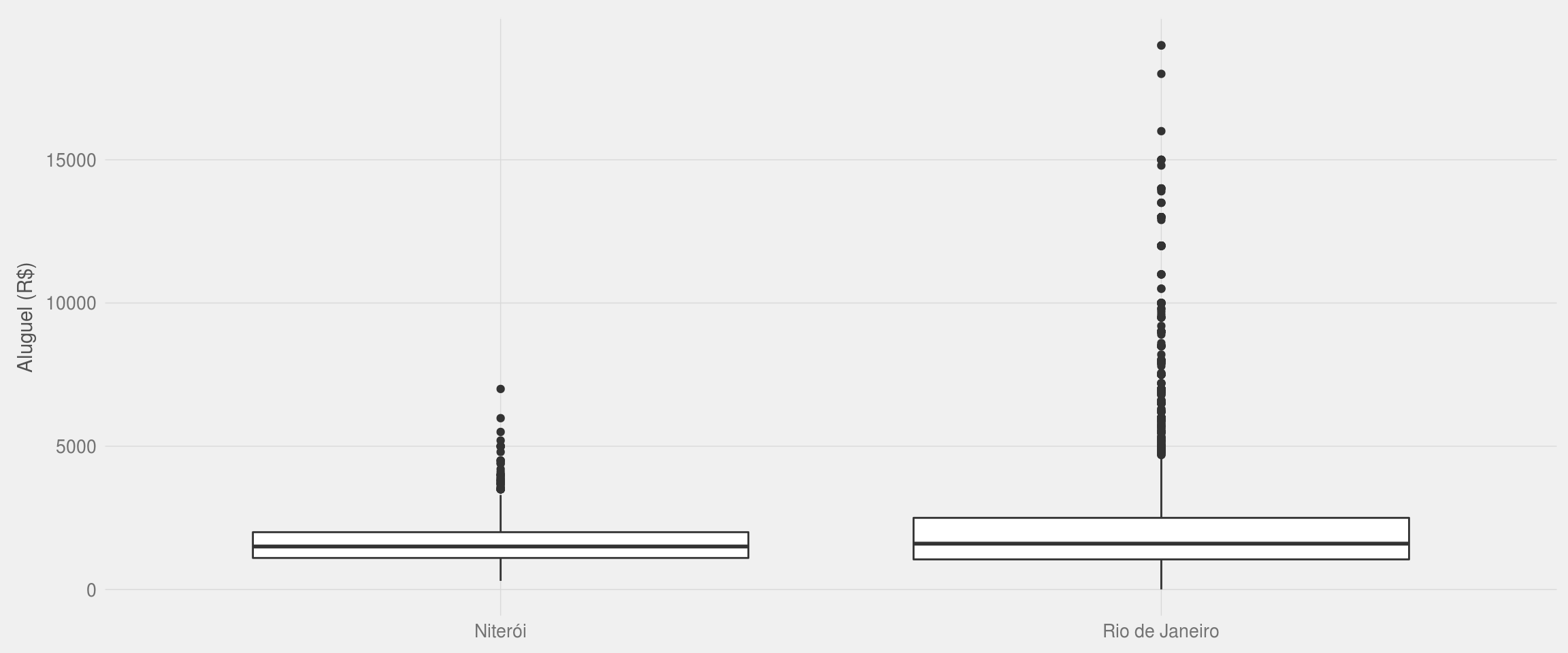
Aparentemente, Niteroi e Rio de Janeiro possuem a mesma mediana do preço de aluguel. A quantidade de apartamentos anormalmente caros é mais comum no Rio de Janeiro. Para confirmar isso:
# utilizando o data frame inteiro e não o filtrado
df %>%
group_by(cidade) %>%
summarise(aluguel_mediano = median(preco, na.rm = TRUE),
aluguel_medio = mean(preco, na.rm = TRUE))## # A tibble: 2 x 3
## cidade aluguel_mediano aluguel_medio
## <chr> <dbl> <dbl>
## 1 Niterói 1500 2513.048
## 2 Rio de Janeiro 1500 2864.210Muito surpreendetemente, Rio de Janeiro e Niterói apresentam exatamente o mesmo aluguel mediano. A existência de muitas anomalias no Rio de Janeiro fazem com que ela apresente um aluguel médio cerca de R$300 maior que Niterói. Será que essa diferença é estatisticamente significante?
aov(preco ~ cidade, data = df) %>% summary()## Df Sum Sq Mean Sq F value Pr(>F)
## cidade 1 1.350e+08 135007106 0.19 0.663
## Residuals 10645 7.566e+12 710771131
## 433 observations deleted due to missingnessO valor p é superior a 0,05, então não podemos afirmar que há uma diferença significativa nos preços de aluguel entre o Rio de Janeiro e Niterói.
Quartos
Em relação ao número de quartos:
df2 %>%
group_by(cidade, qtd_quarto) %>%
#summarise(n = n()) %>%
ggplot(aes(x = qtd_quarto, fill = cidade)) +
geom_bar(position = "fill") +
meu_tema() +
scale_y_continuous(breaks = seq(0, 1, 0.1)) +
labs(x = "Quartos", y = "Porcentual", fill = NULL) +
theme(legend.position = "bottom")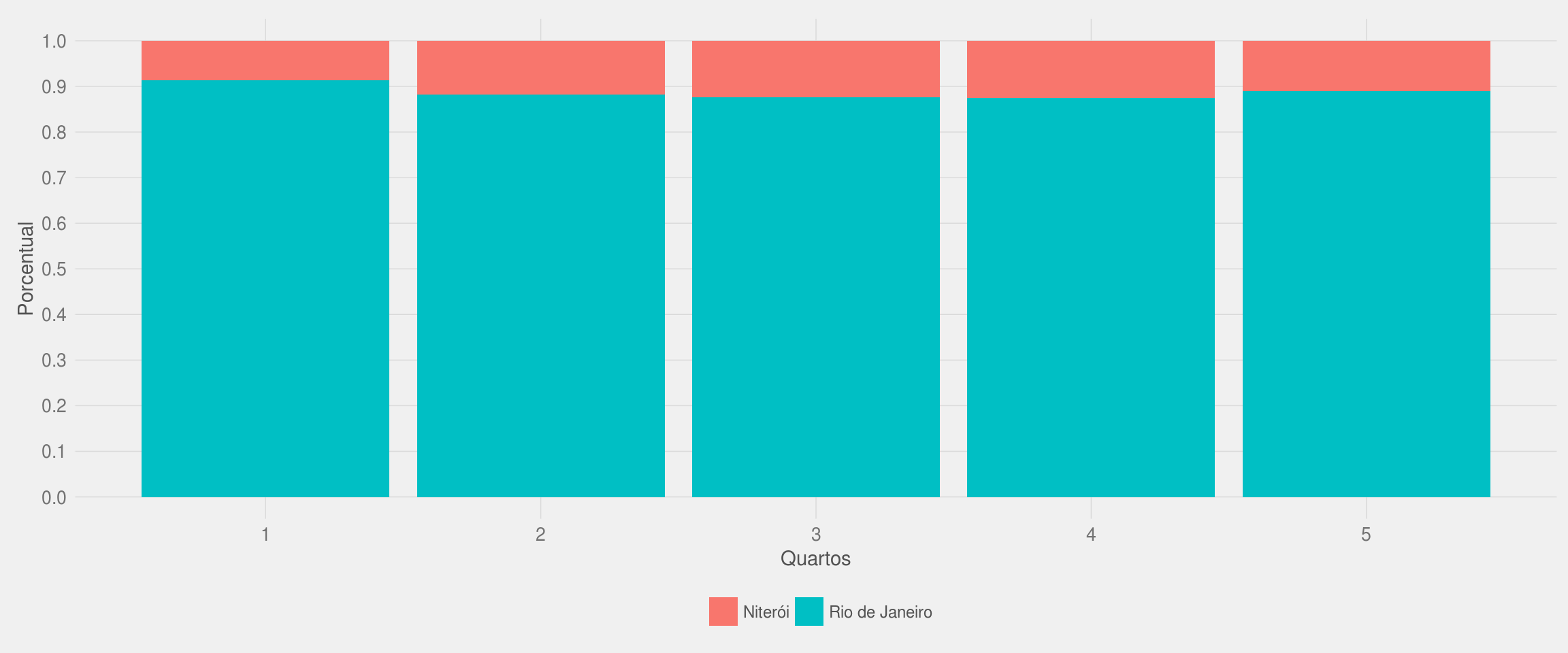
df2 %>%
filter(tem_quarto) %>%
group_by(cidade, qtd_quarto) %>%
#summarise(n = n()) %>%
ggplot(aes(fill = as.character(qtd_quarto), x = cidade)) +
geom_bar(position = "fill") +
meu_tema() +
scale_fill_manual(values = brewer.pal(5, "Reds")) +
scale_y_continuous(breaks = seq(0, 1, 0.1)) +
labs(x = NULL, y = "Porcentual")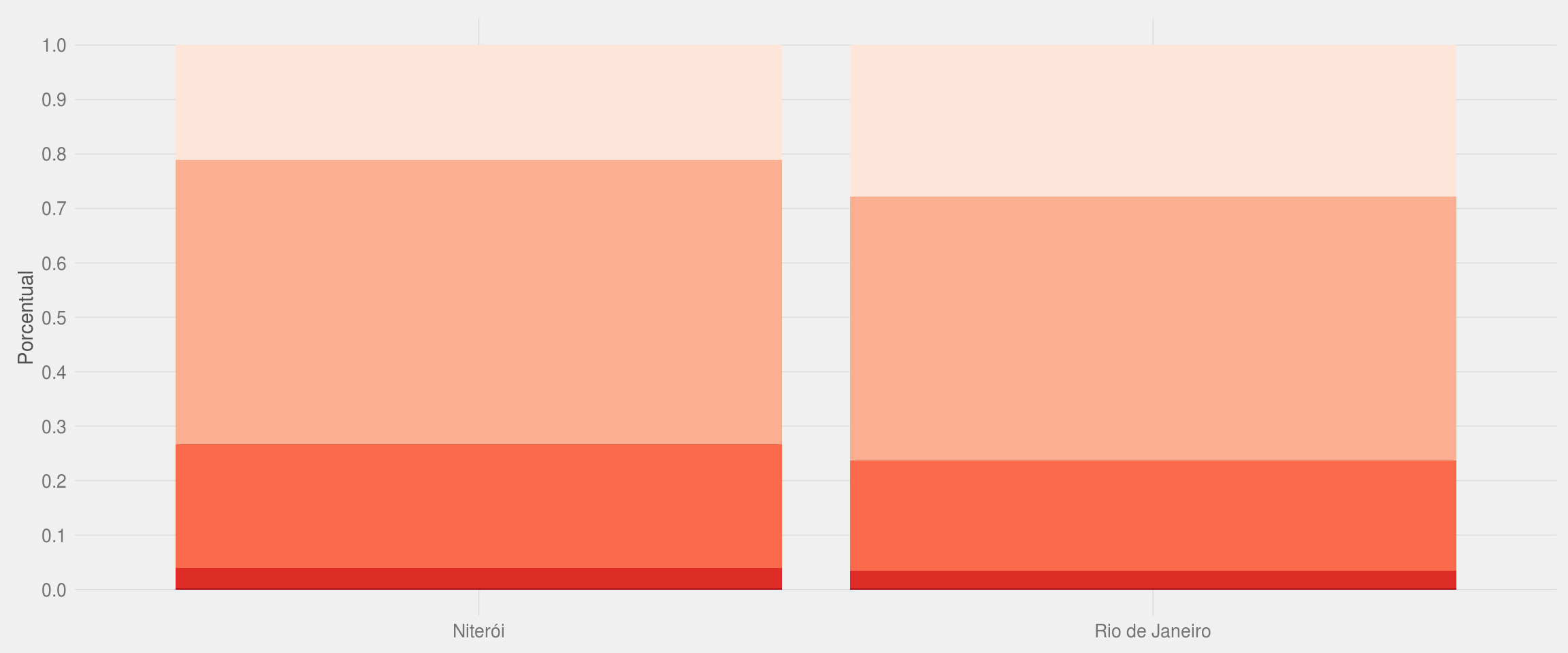
Os dois gráficos acima mostram que os apartamentos para aluguel do Rio de Janeiro costumam ter menos quartos: Cerca de 30% dos imóveis da cidade possuem apenas 1 quarto. A proporção de apartamentos com 2 ou 3 quartos é maior em Niterói do que na capital do estado.
Análise de bairros do Rio de Janeiro
Para esta análise, vamos considerar apenas a cidade do Rio de Janeiro.
Quais os bairros com mais ofertas de apartamento? Quais os com os aluguéis mais caros?
df.rio <- df %>% filter(cidade == "Rio de Janeiro" & preco < 20000)
temp <- df.rio %>%
group_by(cidade, bairro) %>%
summarise(qtd_apt = n(),
aluguel_mediano = median(preco, na.rm = TRUE),
area_mediana = median(area_condominio, na.rm = TRUE)) %>%
arrange(desc(qtd_apt)) %>%
ungroup
head(temp, 10)## # A tibble: 10 x 5
## cidade bairro qtd_apt aluguel_mediano
## <chr> <chr> <int> <dbl>
## 1 Rio de Janeiro Barra da Tijuca 928 2500
## 2 Rio de Janeiro Recreio Dos Bandeirantes 793 1800
## 3 Rio de Janeiro Copacabana 791 2300
## 4 Rio de Janeiro Campo Grande 379 850
## 5 Rio de Janeiro Jacarepaguá 349 1970
## 6 Rio de Janeiro Centro 319 1200
## 7 Rio de Janeiro Tijuca 279 2000
## 8 Rio de Janeiro Botafogo 265 2600
## 9 Rio de Janeiro Flamengo 240 2500
## 10 Rio de Janeiro Taquara 215 1100
## # ... with 1 more variables: area_mediana <dbl>São mais de 150 bairros, então não dá para mostrar todos em uma tabela aqui no post. Talvez uma boa forma de visualizar esses dados seja por meio de um gráfico:
y <- list(title = "Preço mediano do aluguel (R$)")
x <- list(title = "Quantidade de apts. para aluguel")
plot_ly(temp, x = ~qtd_apt, y = ~aluguel_mediano, size = ~area_mediana,
text = ~paste("Bairro: ", bairro)) %>%
layout(title = "Análise de apartamentos para alugar por bairro", xaxis = x, yaxis = y) -> pClique na imagem abaixo para conferir o gráfico interativo.

Conforme mostra o gráfico acima, não dá para dizer que existe relação entre a quantidade de apartamentos disponíveis para alugar em um bairro e o preço do aluguel.
Vamos então mostrar um boxplot com a distribuição de preço de aluguel para os 20 bairros com mais oferta de apartamentos.
temp <- df.rio %>%
group_by(cidade, bairro) %>%
summarise(qtd_imoveis = n(),
aluguel_mediano = median(preco, na.rm = TRUE)) %>%
arrange(desc(qtd_imoveis)) %>%
ungroup %>%
top_n(20, qtd_imoveis)
df.rio %>%
filter(bairro %in% temp$bairro) %>%
ggplot(aes(x = reorder(bairro, preco, FUN = median), y = preco)) +
geom_boxplot() + geom_point(color = "blue", alpha = 5/100) +
meu_tema(axis.text.size = 9) +
coord_flip() +
scale_y_continuous(breaks = seq(0, 20000, 1000)) +
theme(legend.position = "bottom") +
labs(x = NULL, y = "Aluguel (R$)")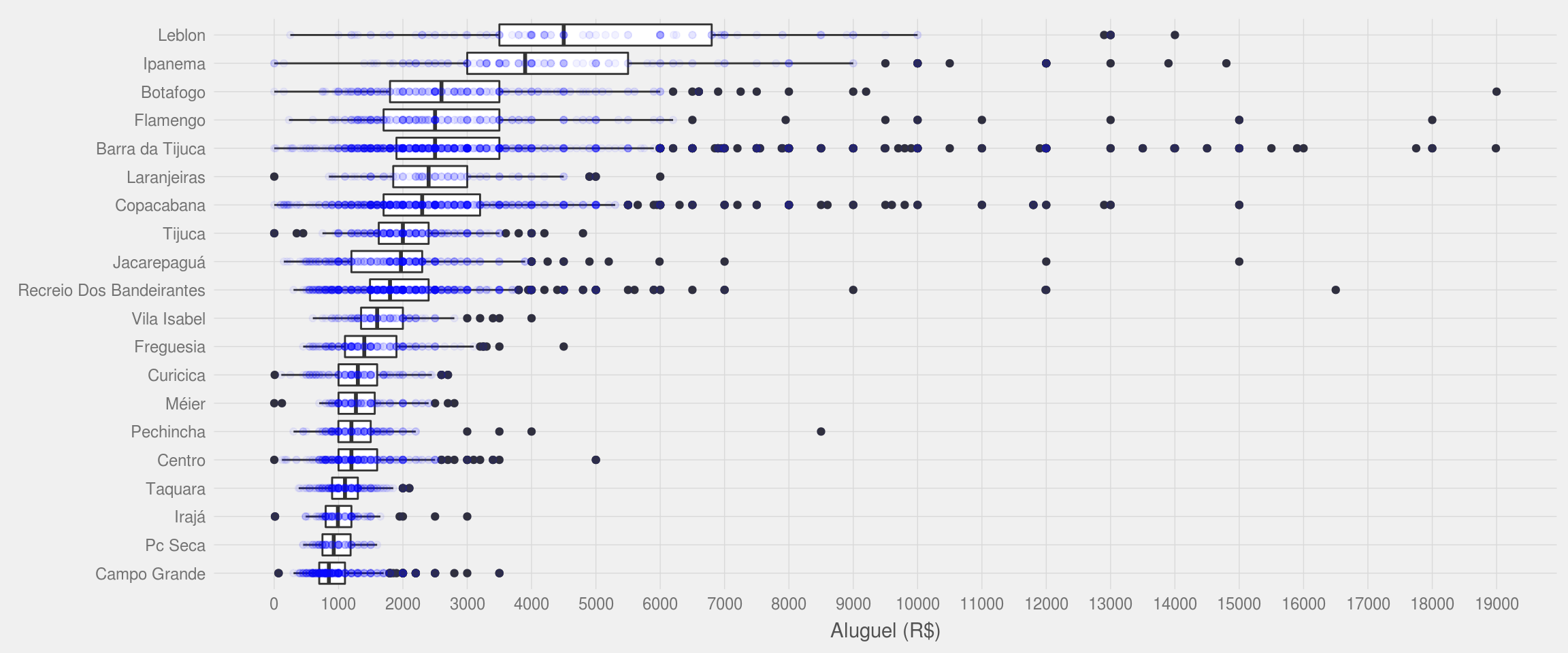
Com o gráfico acima, aprendemos que:
* O aluguel mediano de um apartamento no Leblon é maior que R$4000,00. Contudo, ainda assim é possível encontrar apartamentos cujo valor é o mesmo do mediano encontrado em bairros menos ricos;
* Existem apenas três bairros (dentre os 20 mais populares) onde o preço mediano do aluguel é menor que R$1000,00;
* O bairro onde existe o maior número de anomalias é a Barra da Tijuca. Isso significa que nesse bairro, o valor mediano do aluguel não é um dado muito útil por causa da má-distribuição dos valores e da quantidade de pontos fora da curva.
Em relação à área dos apartamentos, temos:
df.rio %>%
filter(bairro %in% temp$bairro & area_condominio < 300) %>%
ggplot(aes(x = reorder(bairro, area_condominio, FUN = median), y = area_condominio)) +
geom_boxplot() + geom_point(color = "blue", alpha = 5/100) +
meu_tema(axis.text.size = 9) +
coord_flip() +
scale_y_continuous(breaks = seq(0, 300, 50)) +
theme(legend.position = "bottom") +
labs(x = NULL, y = "Aluguel (R$)")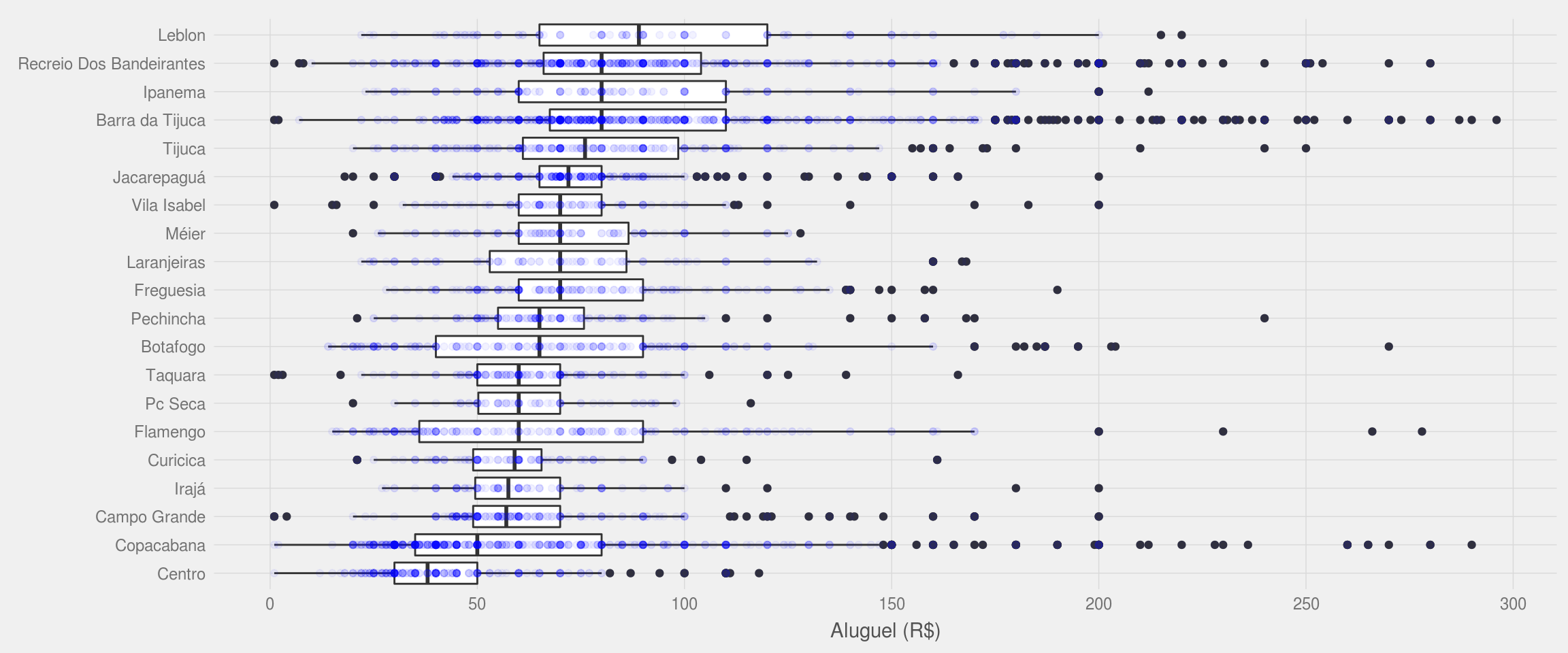
Análise de regressão: O que determina o preço de um aluguel?
Já que temos dados tão legais em mãos, por que não levar a análise a um passo adiante e aplicar uma técnica estatística para tentar explicar o preço do aluguel de um apartamento por meio de variáveis independentes?
Para não ter a complicação de usar uma variável categórica com vários valores diferentes (bairro) em um modelo de regressão, eu construí o modelo apenas para os apartamentos do Centro do Rio de Janeiro.
temp <- df2 %>% select(preco, cidade, bairro, qtd_quarto, taxa_condominio, area_condominio)
temp %<>% filter(cidade == "Rio de Janeiro" & bairro == "Centro")
summary(temp)## preco cidade bairro qtd_quarto
## Min. : 1 Length:271 Length:271 Min. :1.000
## 1st Qu.:1000 Class :character Class :character 1st Qu.:1.000
## Median :1200 Mode :character Mode :character Median :1.000
## Mean :1376 Mean :1.232
## 3rd Qu.:1600 3rd Qu.:1.000
## Max. :5000 Max. :3.000
##
## taxa_condominio area_condominio
## Min. : 0.0 Min. : 1.0
## 1st Qu.: 300.0 1st Qu.: 30.0
## Median : 380.0 Median : 38.0
## Mean : 384.1 Mean : 42.3
## 3rd Qu.: 452.0 3rd Qu.: 50.0
## Max. :1500.0 Max. :118.0
## NA's :24z <- lm(preco ~ qtd_quarto + taxa_condominio + area_condominio, data = temp)
summary(z)##
## Call:
## lm(formula = preco ~ qtd_quarto + taxa_condominio + area_condominio,
## data = temp)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1223.54 -251.40 -48.26 195.50 2010.33
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 386.16410 81.99771 4.709 4.18e-06 ***
## qtd_quarto 273.17100 99.11117 2.756 0.00629 **
## taxa_condominio 0.02677 0.17921 0.149 0.88136
## area_condominio 15.01647 2.49506 6.018 6.45e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 439.8 on 243 degrees of freedom
## (24 observations deleted due to missingness)
## Multiple R-squared: 0.4838, Adjusted R-squared: 0.4774
## F-statistic: 75.9 on 3 and 243 DF, p-value: < 2.2e-16Alguns comentários sobre o resultado da regressão:
* O valor do R² é de 0,4838, não muito alto;
* A taxa do condomínio, surpreendentemente, não influencia grandemente o valor do aluguel.
Considerações finais
Ainda assim, não respondemos a principal pergunta desta série de posts: como escolho um lugar para morar a partir desses dados? Com as análises acima, conseguimos descobrir algumas coisas interessantes sobre o Rio de Janeiro, mas isso não nos ajuda muito a escolher um lugar para morar. Isso vai ficar para os próximos dois posts.