Introdução
Recentemente, li um artigo sobre a Balcanização dos serviços de streaming que me fez refletir sobre essa indústria. Dado que assinar mais de um serviço de streaming pode ser um desperdício, devido a falta de tempo para consumir tanto material, as pessoas costumam optar por apenas um dos existentes: Netflix, Amazon Prime Video ou algum outro. Como saber qual escolher?
O serviço JustWatch ajuda um pouco. Nele, é possível pesquisar por um filme ou seriado e descobrir em quais serviços ele está disponível. Assim, se temos em mão os dados dos catálogos dos serviços, podemos avaliar a quantidade e qualidade dos filmes em cada um para decidir o melhor.
Existe um módulo Python que permite extrair os dados do JustWatch em json, tornando os dados muito fáceis para trabalhar. Por isso, este projeto usará código não só em R como em Python.
Este projeto consiste em coletar os 5000 melhores filmes e seriados do IMDB, coletar dados de cada usando a API do Justwatch e analisar os resultados para concluir sobre o melhor serviço de streaming no Brasil.
Primeiro passo: Coletando nomes de filmes e seriados
Infelizmente, a API do Justwatch não nos permite coletar todo o catálogo do site, existindo um limite dos 1000 primeiros resultados, mesmo que se altere os parâmetros page e page_size da função.
Por outro lado, a função não impõe um limite de requisições feitas sequencialmente. Por isso, a melhor estratégia é iterar a função sobre uma lista de filmes a pesquisar.
Onde coletar essa lista de filmes? A ideia que eu tive foi usar o IMDB para isso. Eu coletei os 5000 melhores filmes e seriados (sem distinção) para ter os resultados. Como o código é relativamente simples e os dados bem grandes, não vou descrever essa parte do projeto aqui. Os interessados podem consultar como eu fiz para coletar os dados do IMDB neste gist.
Usar o módulo Python para coletar dados da API do JustWatch
O código é bem simples: eu leio o arquivo com a lista de filmes salvos na parte anterior, itero sobre o dataframe, junto todos os resultados em um dicionário e salvo os dados em formato json.
O comportamento da função just_watch.search_for_item() é o mesmo de você pesquisar manualmente no site. Isto é, ao digitar na caixa de busca o título desejado, aparecerá uma lista com os resultados relacionados, sendo que provavelmente apenas o primeiro resultado é o que interessa. Por isso, no código abaixo, eu extraio o primeiro resultado da busca. Funciona na maioria das vezes.
from justwatch import JustWatch
import csv
import json
import pandas as pd
just_watch = JustWatch(country='BR')
# ler lista de filmes
arquivo = '/home/sillas/R/data/imdb/lista_filmes_imdb.csv'
titulos = pd.read_csv(arquivo)
out = list()
for index, row in titulos.iterrows():
# imprimir status do loop
if index % 100 == 0:
print(index)
# consultar api
api_data = just_watch.search_for_item(query = row["full_title"])["items"]
# salvar dados apenas se houver resultado
if len(api_data) > 0:
first_item_data = api_data[0]
first_item_data["tconst"] = row["tconst"]
out.append(first_item_data)
# salvar resultados em json
with open('/home/sillas/R/data/imdb/justwatchdata.json', 'w') as fp:
json.dump(out, fp)
# salvar dados de sites de streaming
provider_details = just_watch.get_providers()
with open('/home/sillas/R/data/imdb/justwatchdata_providers.json', 'w') as fp:
json.dump(provider_details, fp)Juntando os dados
Finalmente, chegamos à parte divertida. Abaixo eu importo os pacotes usados e o arquivo json salvo acima.
library(tidyverse)
library(jsonlite)
library(UpSetR)
library(ggridges)
# gist com o json:
jw <- jsonlite::fromJSON("/home/sillas/R/data/imdb/justwatchdata.json") %>%
as_tibble() %>%
# selecionar colunas importantes
select(tconst, original_title, original_release_year,
tmdb_popularity, object_type, offers, scoring)
glimpse(jw)## Observations: 4,442
## Variables: 7
## $ tconst <chr> "tt0903747", "tt0111161", "tt0068646", "tt…
## $ original_title <chr> "Breaking Bad", "The Shawshank Redemption"…
## $ original_release_year <int> 2008, 1994, 1972, 2013, 1974, 1994, 1993, …
## $ tmdb_popularity <dbl> 76.613, 30.009, 26.993, 82.621, 19.567, 32…
## $ object_type <chr> "show", "movie", "movie", "show", "movie",…
## $ offers <list> [<data.frame[5 x 14]>, <data.frame[13 x 1…
## $ scoring <list> [<data.frame[4 x 2]>, <data.frame[10 x 2]…A estrutura deste dataframe não é necessariamente tabular, como se costuma ver. As colunas offers e scoring são da classe list, pois cada valor dessas duas variáveis é um dataframe. Ou seja, no R é possível termos dataframes dentro de um dataframe.
Para tornar o dataframe mais simples de ser usado, vamos transformar essas duas colunas em dataframes separados.
# criar funcao para extrair apenas as colunas importantes de offers
extract_offers_data <- function(offers){
if(!is.null(offers)){
offers %>%
select(monetization_type, provider_id,
date_created, presentation_type)
}
}
tbl_offers <- jw %>%
select(tconst, offers) %>%
# remover filmes sem dados de streaming
filter(!map_lgl(offers, is.null)) %>%
# usar funcao criada acima para extrair colunas
mutate(offers = map(offers, extract_offers_data)) %>%
unnest(offers) %>%
# filtrar apenas filmes de serviços onde se paga uma taxa mensal para ter
# acesso aos filmes, ao inves de um preço para cada filme, como se fosse
# uma loja.
filter(monetization_type == "flatrate") %>%
distinct(tconst, provider_id)
tbl_scoring <- jw %>%
select(tconst, scoring) %>%
filter(!map_lgl(scoring, is.null)) %>%
unnest(scoring) %>%
rename(scoring_provider_type = provider_type)
# no dataframe principal, remover essas duas colunas
tbl_jw <- jw %>%
select(-c(offers, scoring))
# importar arquivos com os metadados dos sites de streaming
tbl_providers <- fromJSON("/home/sillas/R/data/imdb/justwatchdata_providers.json") %>%
as_tibble() %>%
select(provider_id = id, provider_name = slug) %>%
mutate(provider_name = str_replace_all(provider_name, "-", "_"))
tbl_offers_prov <- left_join(tbl_offers, tbl_providers, by = "provider_id")
# criar dataset das analises
tbl_jw <- tbl_jw %>%
left_join(tbl_offers_prov, by = "tconst") %>%
left_join(tbl_scoring, by = "tconst") %>%
select(-provider_id)Este é o dataset das nossas análises:
# dataset das analises
tbl_jw## # A tibble: 41,085 x 8
## tconst original_title original_releas… tmdb_popularity object_type
## <chr> <chr> <int> <dbl> <chr>
## 1 tt090… Breaking Bad 2008 76.6 show
## 2 tt090… Breaking Bad 2008 76.6 show
## 3 tt090… Breaking Bad 2008 76.6 show
## 4 tt090… Breaking Bad 2008 76.6 show
## 5 tt011… The Shawshank… 1994 30.0 movie
## 6 tt011… The Shawshank… 1994 30.0 movie
## 7 tt011… The Shawshank… 1994 30.0 movie
## 8 tt011… The Shawshank… 1994 30.0 movie
## 9 tt011… The Shawshank… 1994 30.0 movie
## 10 tt011… The Shawshank… 1994 30.0 movie
## # … with 41,075 more rows, and 3 more variables: provider_name <chr>,
## # scoring_provider_type <chr>, value <dbl>Resultados
Quais sites possuem mais filmes e seriados?
tbl_jw %>%
distinct(tconst, object_type, provider_name) %>%
count(provider_name, object_type) %>%
group_by(object_type) %>%
mutate(pct = 100 * n/sum(n)) %>%
ggplot(aes(x = fct_rev(provider_name), y = pct)) +
geom_col() +
coord_flip() +
facet_wrap(~ object_type, ncol = 1) +
labs(x = NULL, y = "%",
title = "Presença dos melhores filmes e seriados \nnos sites de streaming no Brasil") +
theme_bw()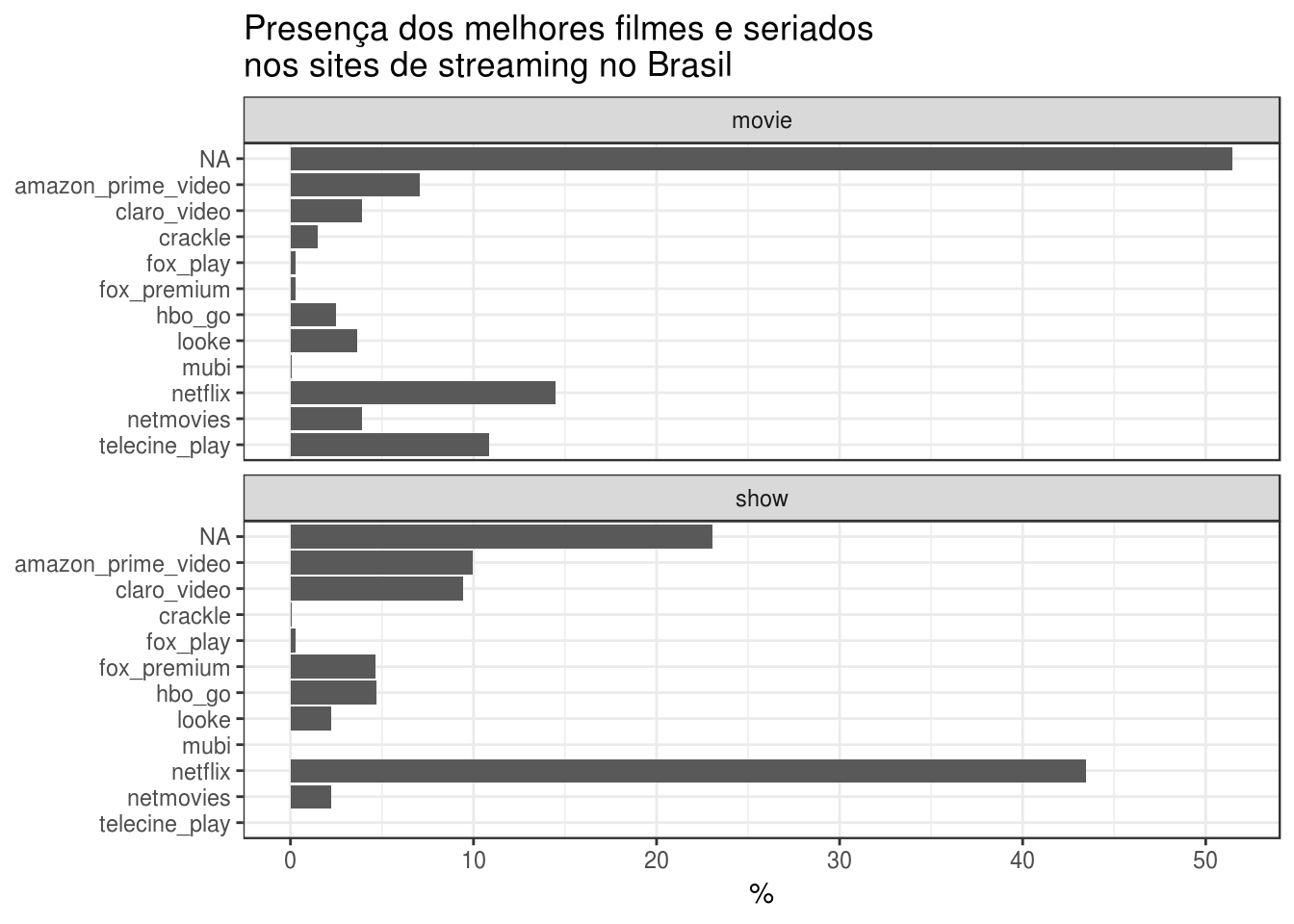
Os resultados são bem interessantes. Para quem adora seriados, a Netflix reina absoluta tendo em seu portfolio 40% dos melhores seriados, enquanto que o segundo melhor neste quesito, o Amazon Prime Video, possui apenas 10%. Em termos de filmes, a Netflix também é a melhor, sendo seguida de perto pelo Telecine Play. O portfolio do Amazon Prime Video para filmes deixa bastante a desejar.
Ainda sobre filmes, é bastante importante mencionar que mais da metade das produções não está disponível em nenhum serviço de streaming de vídeo por assinatura no Brasil, um resultado bem lamentável para cinéfilos.
Para o restante deste post, vamos focar apenas nesses 3 principais streamings:
prvs <- c("netflix", "amazon_prime_video", "telecine_play")
tbl_jw_principais <- tbl_jw %>%
filter(is.na(provider_name) | provider_name %in% prvs) %>%
mutate(provider_name = tidyr::replace_na(provider_name, "nenhum"))Quais sites possuem os filmes mais recentes?
range(tbl_jw_principais$original_release_year)## [1] 1920 2019tbl_jw_principais %>%
ggplot(aes(x = original_release_year, color = provider_name)) +
stat_ecdf() +
theme_bw() +
scale_x_continuous(breaks = seq(1920, 2020, by = 10),
minor_breaks = NULL) +
scale_y_continuous(breaks = seq(0, 1, .1),
minor_breaks = NULL,
labels = scales::percent) +
theme(legend.position = "bottom") +
facet_wrap(~ object_type, ncol = 2) +
labs(title = "Distribuição da idade de títulos por serviço de streaming",
x = NULL,
y = NULL)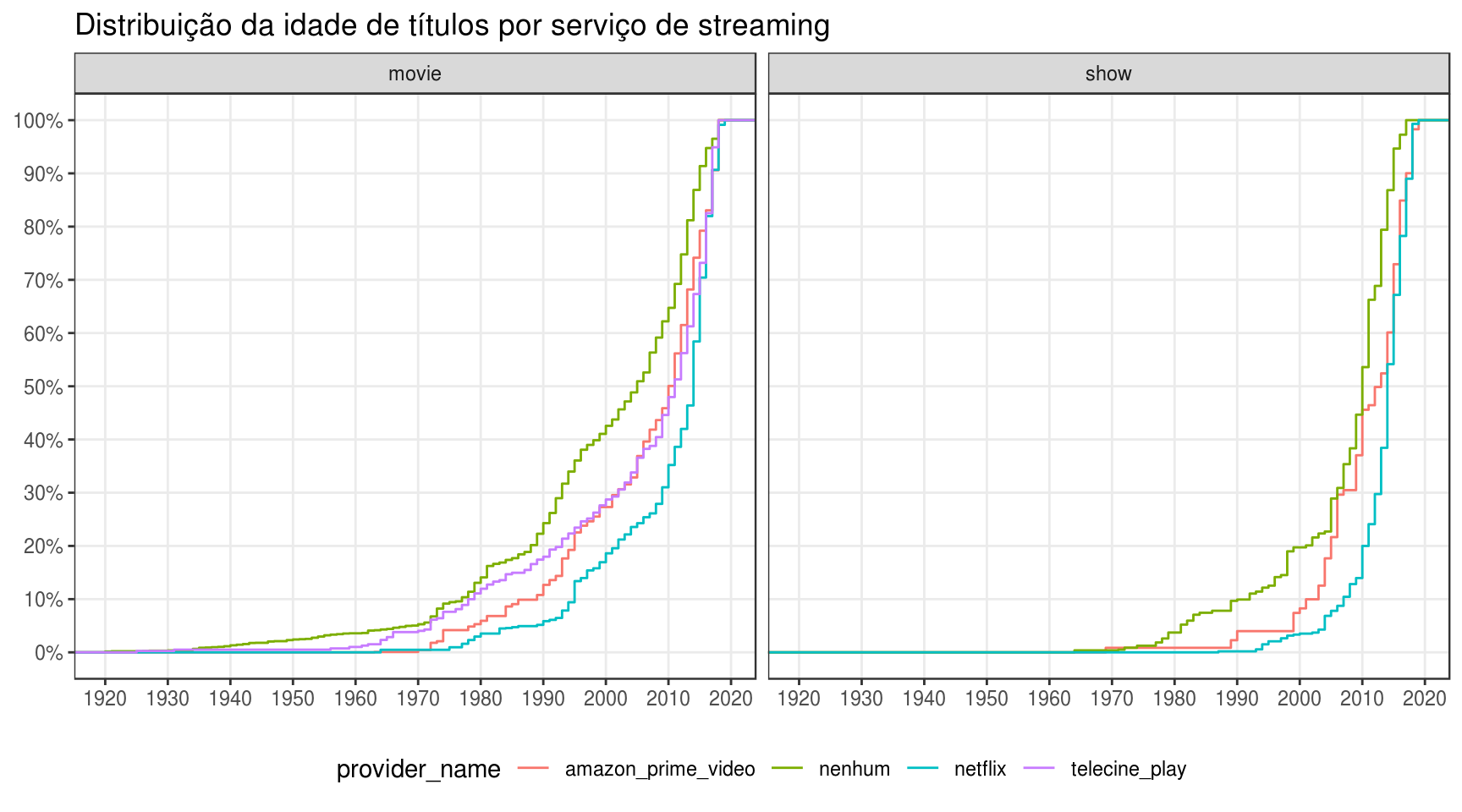
O formato da curva referente à Netflix é muito interessante. Note como ela cresce numa velocidade muito maior a partir de 2010. Olhando para este ponto no eixo vertical, nota-se que 70% dos filmes e incríveis 80% dos seriados foram lançados a partir de 2010. De todos os 3 serviços de streaming, a Netflix é a mais enviesada para produções recentes. Note também como 70% dos filmes que não estão presentes em nenhum serviço por assinatura foram lançados antes de 2010. Na verdade, Netflix e Amazon Prime Video não possuem nenhum filme lançado antes de 1960.
Outra maneira de visualizar os resultados acima é separando os anos por década:
tbl_jw_principais %>%
mutate(decada = as.character(round(original_release_year %/% 10) * 10)) %>%
count(decada, object_type, provider_name) %>%
ggplot(aes(x = decada, y = n, fill = provider_name)) +
geom_col(position = position_dodge()) +
theme_bw() +
labs(title = "Quantidade de títulos por década",
x = NULL,
y = NULL) +
facet_wrap(~ object_type, scales = "free_y", ncol = 1) +
theme(legend.position = "bottom")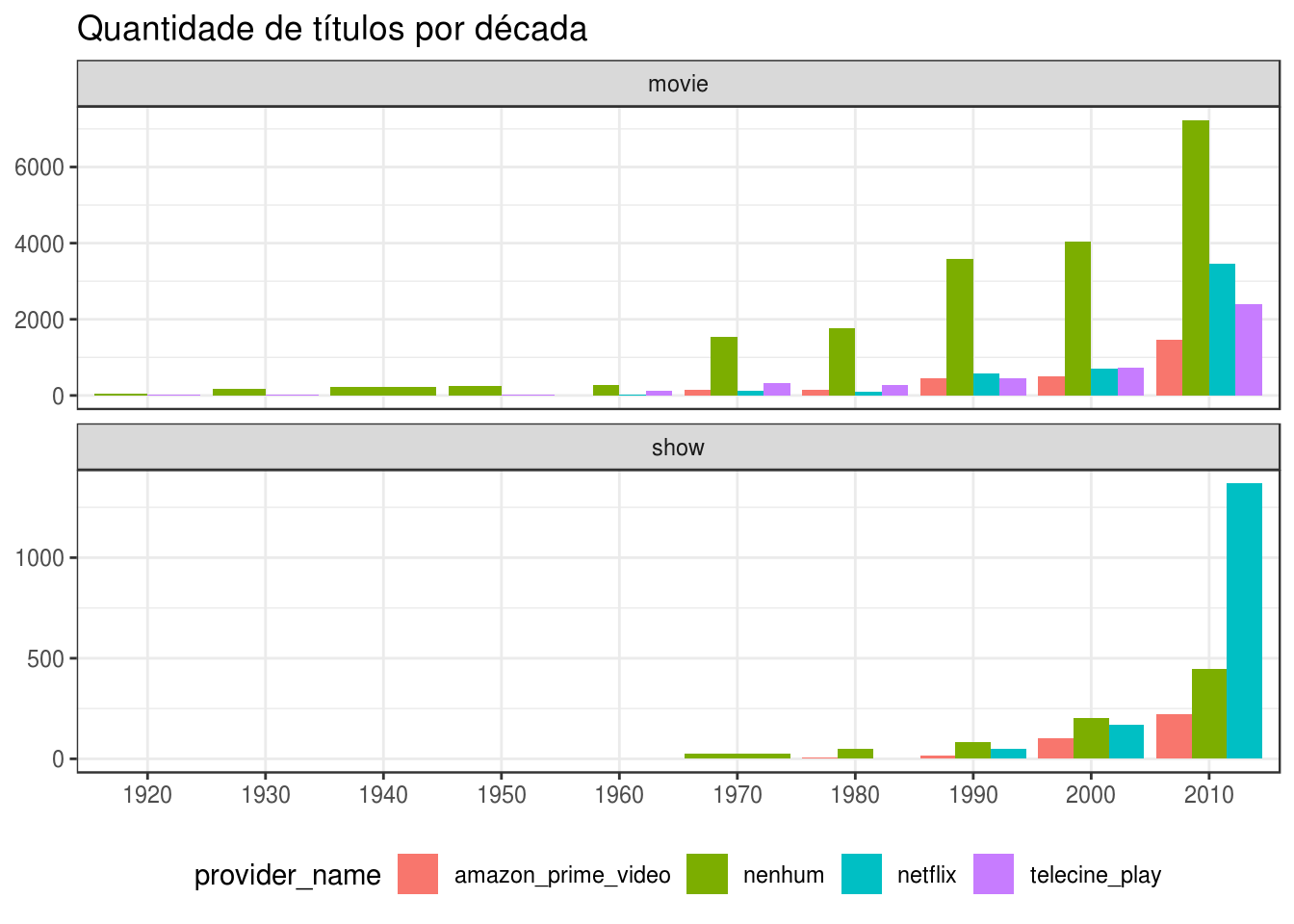
Qualidade dos filmes
Como parâmetro para qualidade dos filmes, usei a nota do IMDB, que também é fornecida no dataset do JustWatch.
tbl_jw_principais %>%
# filtrar filmes com nota IMDB acima de 7 para eliminar entradas erradas
filter(scoring_provider_type == "imdb:score", value >= 7) %>%
mutate(value = cut(value, breaks = 0:10)) %>%
count(object_type, provider_name, value) %>%
ggplot(aes(x = value, y = n, fill = provider_name)) +
geom_col(position = position_fill()) +
theme_bw() +
scale_y_continuous(breaks = seq(0, 1, .1),
labels = scales::percent) +
facet_wrap(~ object_type) +
labs(x = NULL,
y = NULL,
title = "Percentual de títulos por faixa de nota no IMDB") +
theme(legend.position = "bottom")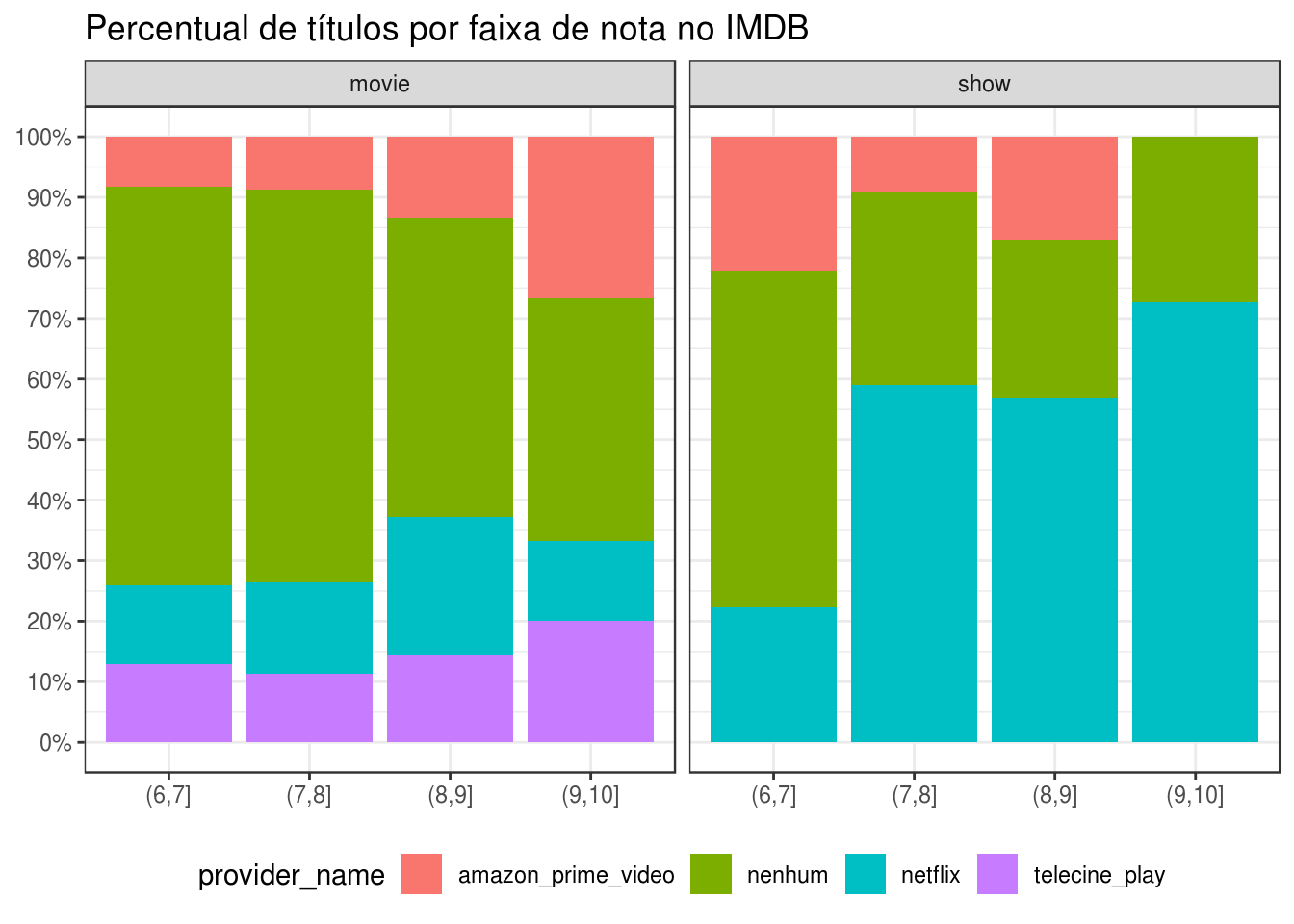
Não aparenta haver diferença em relação à nota dos filmes e seriados de acordo com o streaming.
Exclusividade de conteúdo
Por último, mas não menos importante, existe o critério de exclusividade entre as plataformas, algo comum nesta indústria. Quantos filmes estão presentes apenas, por exemplo no Telecine Play? Quantos são possíveis de encontrar em mais de uma plataforma?
# criar matriz binaria
tbl_jw_principais_wide <- tbl_jw_principais %>%
distinct(tconst, provider_name) %>%
mutate(provider_name = replace_na(provider_name, "nenhum")) %>%
mutate(tem = 1) %>%
spread(provider_name, tem) %>%
mutate_at(vars(-tconst), replace_na, 0) %>%
as.data.frame()
# grafico upset
upset(tbl_jw_principais_wide, nsets = 10,
mainbar.y.label = NULL)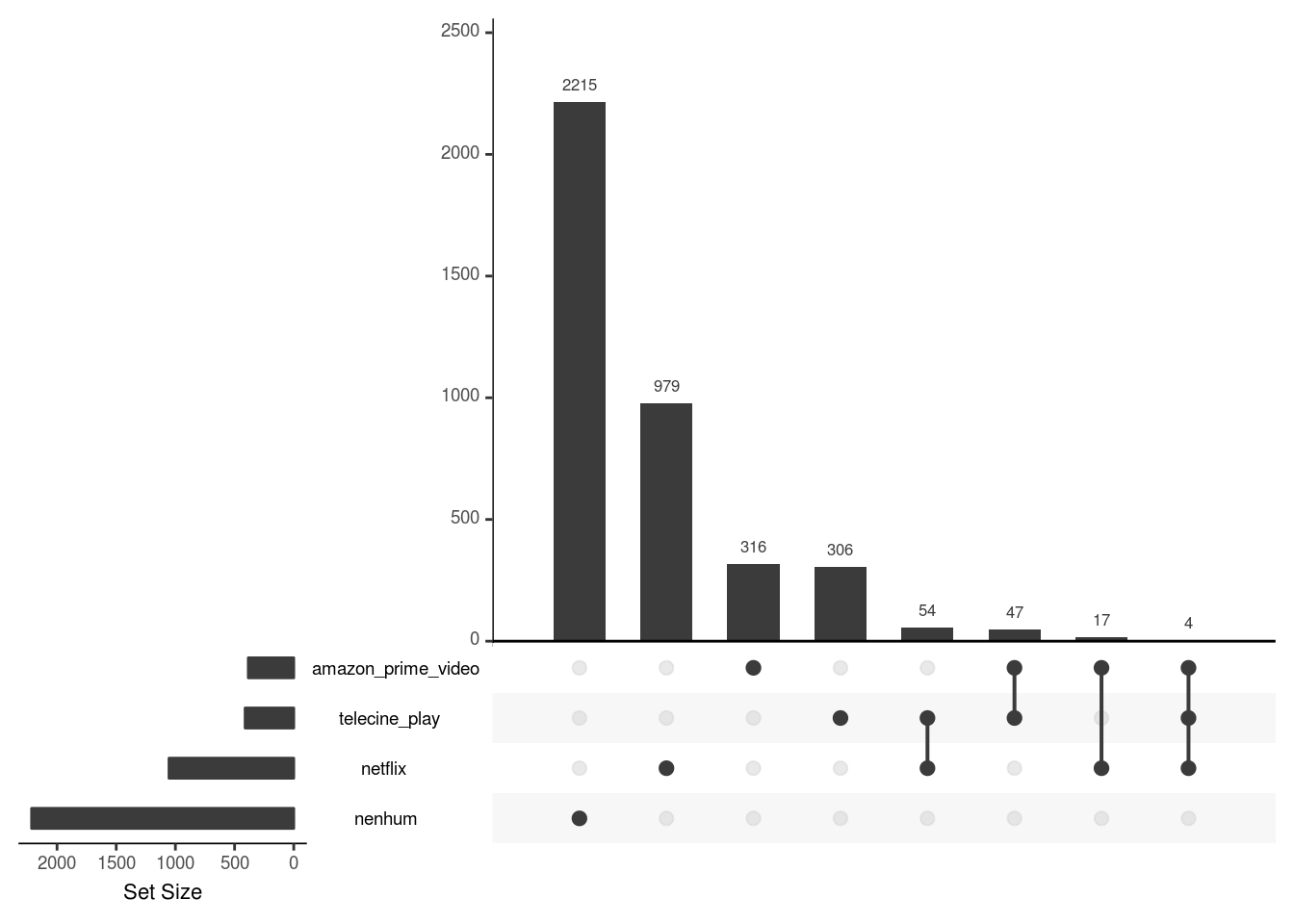
Também neste quesito a Netflix é disparado o melhor dentre os 3. 979 dos títulos são exclusivos da Netflix, muito mais que a soma dos outros dois serviços. É curioso que exista pouquíssima interseção entre as plataformas: apenas 17 títulos estão presentes tanto na Netflix como no Amazon Prime Video.
Bônus: Diagrama de Venn
Outra forma de visualizar os resultados acima é por meio de um diagrama de Venn:
lst <- tbl_jw_principais %>%
distinct(tconst, provider_name) %>%
split(.$provider_name) %>%
map("tconst")
gplots::venn(lst)
Conclusão
Usando o universo dos 5000 melhores títulos de filmes e seriados de acordo com o IMDB, a Netflix é bem superior às concorrentes no Brasil.