Recentemente, quando estava no trabalhando lendo uma revista de negócios sobre o varejo, me deparei com o seguinte gráfico:
knitr::include_graphics("https://i.imgur.com/f1dh4uw.jpg")
Mesmo sem contexto, é possível perceber que essa visualização foi criada para mostrar a divergência de opiniões sobre a importância dada a fatores de compra pelos executivos de varejo e pelos consumidores. Imediatamente, eu pensei que o jornalista perdeu uma ótima oportunidade de representar melhor a informação desejada.
Primeiramente, a ordem dos fatores no gráfico não segue uma ordem clara. Se o gráfico foi feito para enfatizar essa divergência de opiniões, teria sido melhor que os fatores fossem ordenados no gráfico pela diferença numérica entre executivos e consumidores. Veja que o ponto onde há maior disparidade, Acesso a informações, venda e serviços, aparece no canto inferior direito, fazendo com que os olhos do leitor tenham de percorrer o gráfico quase que até seu final para extrair sua informação mais importante. Além disso, o fator de compra que apresenta maior uniformidade, Informações em tempo real sobre inventário e disponibilidade de informações, aparece logo ao lado da que apresenta mais divergência.
Outra oportunidade perdida é que não é dada uma ênfase ao que os consumidores, os responsáveis pela empresa existir, preferem. Como esta é uma revista voltada para o segmento de varejo, seu público-alvo são executivos do setor, que estão sedentos por saber o que os clientes pensam. Contudo, os fatores que os consumidores mais preferem, Pagamento simples e fluido e Acesso a informaçoes, venda e serviços, aparecem em ordem aleatória no gráfico (em quinto e em oitavo lugar, respectivamente).
Por isso, este post é dedicado a propor uma nova versão dessa visualização de dados, de maneira que atenda aos pontos citados acima. Ou seja, um gráfico que:
- Ordene os fatores de acordo com o grau de divergência entre consumidores e executivos;
- Destaque de alguma maneira os fatores que os consumidores consideram mais importantes que os executivos.
library(tidyverse)Recriando o dataset do gráfico:
df <- tribble(
~fator, ~Executivos, ~Consumidores,
"Experiência personalizada", 43, 27,
"Experiência fluida em todos os canais", 42, 26,
"Pagamento simples e fluido", 41, 50,
"Tecnologia em loja", 38, 18,
"Informações em tempo real sobre inventário e disponibilidade de informações", 37, 38,
"Plataformas mobile e aplicativos de compra", 36, 19,
"Habilidade de customizar produtos e serviços", 35, 24,
"Engajamento e presença em redes sociais", 35, 14,
"Pagamento digital e opções de câmbio", 34, 31,
"Acesso a informações, venda e serviços", 31, 50,
"Gamificação e experiência digital interativa", 21, 9
)Em seguida, calculamos a diferença entre as duas colunas numéricas e usamos a funçao forcats::fct_reorder() para ordenar os fatores de acordo com essa diferença.
df <- df %>%
mutate(diferenca = abs(Executivos - Consumidores),
# Quebrar o string do fator em parágrafos e reordenar
fator = str_wrap(fator, 40),
fator = fct_reorder(fator, diferenca, .desc = FALSE)) %>%
# criar colunas para armazenar os valores maximo e minimo entre executivos e consumidores
rowwise() %>%
mutate(maior_percentual = max(Executivos, Consumidores),
menor_percentual = min(Executivos, Consumidores))
# criar coluna para identificar O código desse gráfico é um pouco mais complexo do que o usual. Como eu queria que o label de cada ponto ficasse à esquerda no caso do menor número e à direita do maior, é necessário criar duas camadas de geom_text() separadamente, uma para o valor mínimo de cada fator e outra para o valor máximo, sendo que cada possui um valor diferente de hjust.
df.long <- df %>%
# transformar para formato tidy (long)
gather(fonte_opiniao, valor, 2:3)
p <- ggplot(df.long, aes(x = valor, y = fator)) +
geom_point(aes(color = fonte_opiniao), size = 3) +
# ajustar pontos
scale_x_continuous(limits = c(0, 55), breaks = seq(0, 50, 10)) +
# mudar aparencia. isso é opcional.
theme_minimal() +
# adicionar manualmente o label do valor que cada ponto representa
geom_text(data = df, aes(x = maior_percentual, label = maior_percentual), hjust = -0.3) +
geom_text(data = df, aes(x = menor_percentual, label = menor_percentual), hjust = 1.4) +
# mudar titulos dos eixos e do grafico
labs(x = "%", y = NULL, color = NULL, title = "Quais fatores influenciam a compra?") +
theme(legend.position = "bottom")
p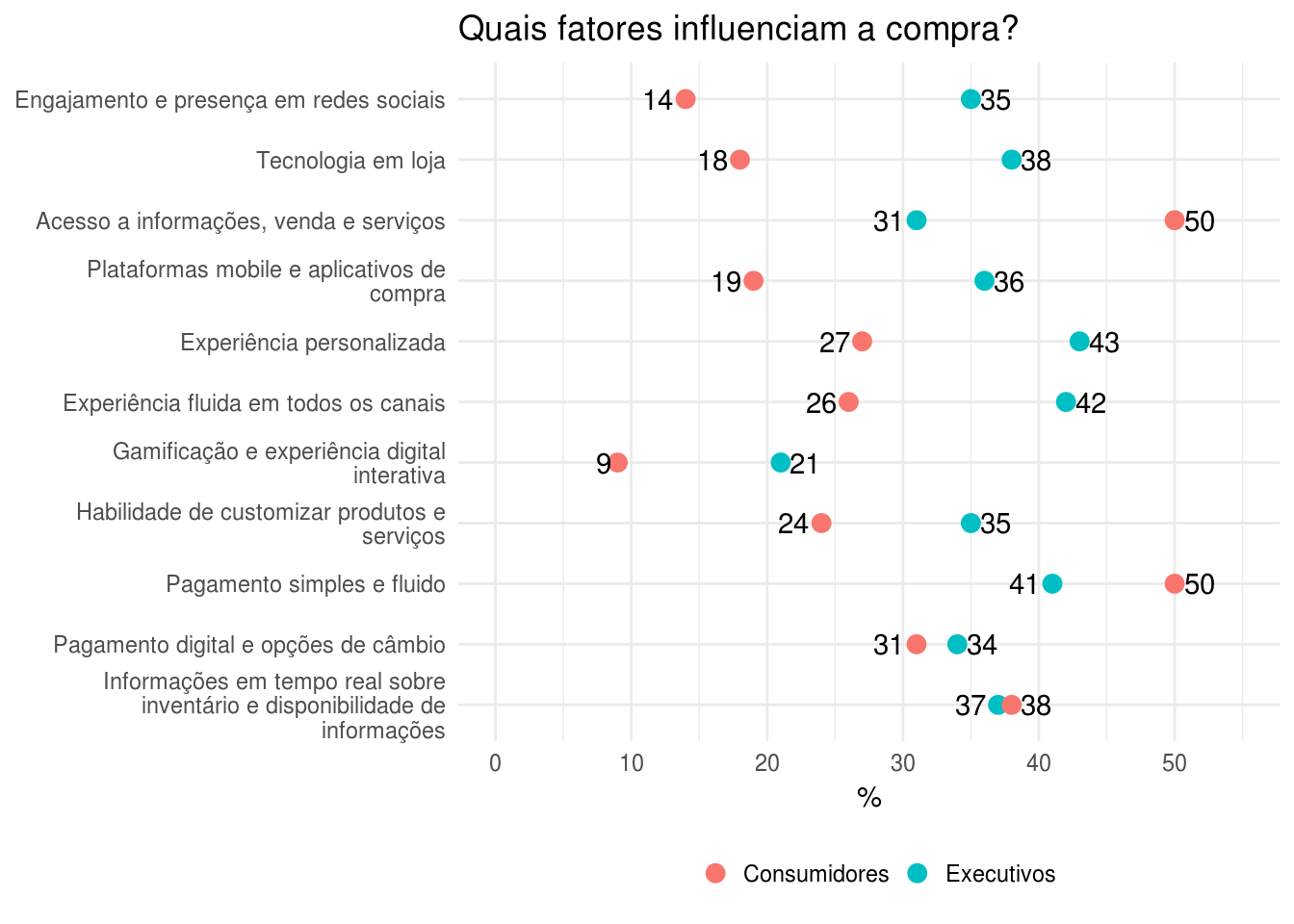
Com este gráfico, creio que atendemos ao primeiro ponto. Veja que, além dos objetivos listados anteriormente, o gráfico apresenta outras melhorias em relação ao original. Uma delas é que é possível descobrir muito mais facilmente quais são os fatores que os consumidores menos se lembram (Gamificação).
Para atender à segunda melhoria proposta, a de destacar de alguma maneira os fatores considerados mais importantes pelos consumidores, decidi usar o seguinte método: plotar um segmento ligando os pontos em cada fator, sendo que, nos fatores de compra que foram mais lembrados por consumidores do que por executivos, o segmento fosse mais destacado (ou menos transparente) no gráfico.
Para isso, vamos criar uma coluna onde o valor do alpha do segmento, que correspondência ao seu nível de opacidade, seja definido manualmente:
# criar coluna para identificar quem da mais importancia ao fator
df <- df %>%
mutate(alpha_segmento = if_else(Executivos - Consumidores > 0, 0.2, 1))Vamos então adicionar esse novo elemento no gráfico.
p +
# para não fazer que o segmento fique em cima do ponto, eu removo 0,3 de cada lado dele
geom_segment(data = df, aes(x = maior_percentual-0.3, xend = menor_percentual+0.3,
y = fator, yend = fator,
alpha = alpha_segmento),
inherit.aes = FALSE, show.legend = FALSE) +
scale_alpha_identity()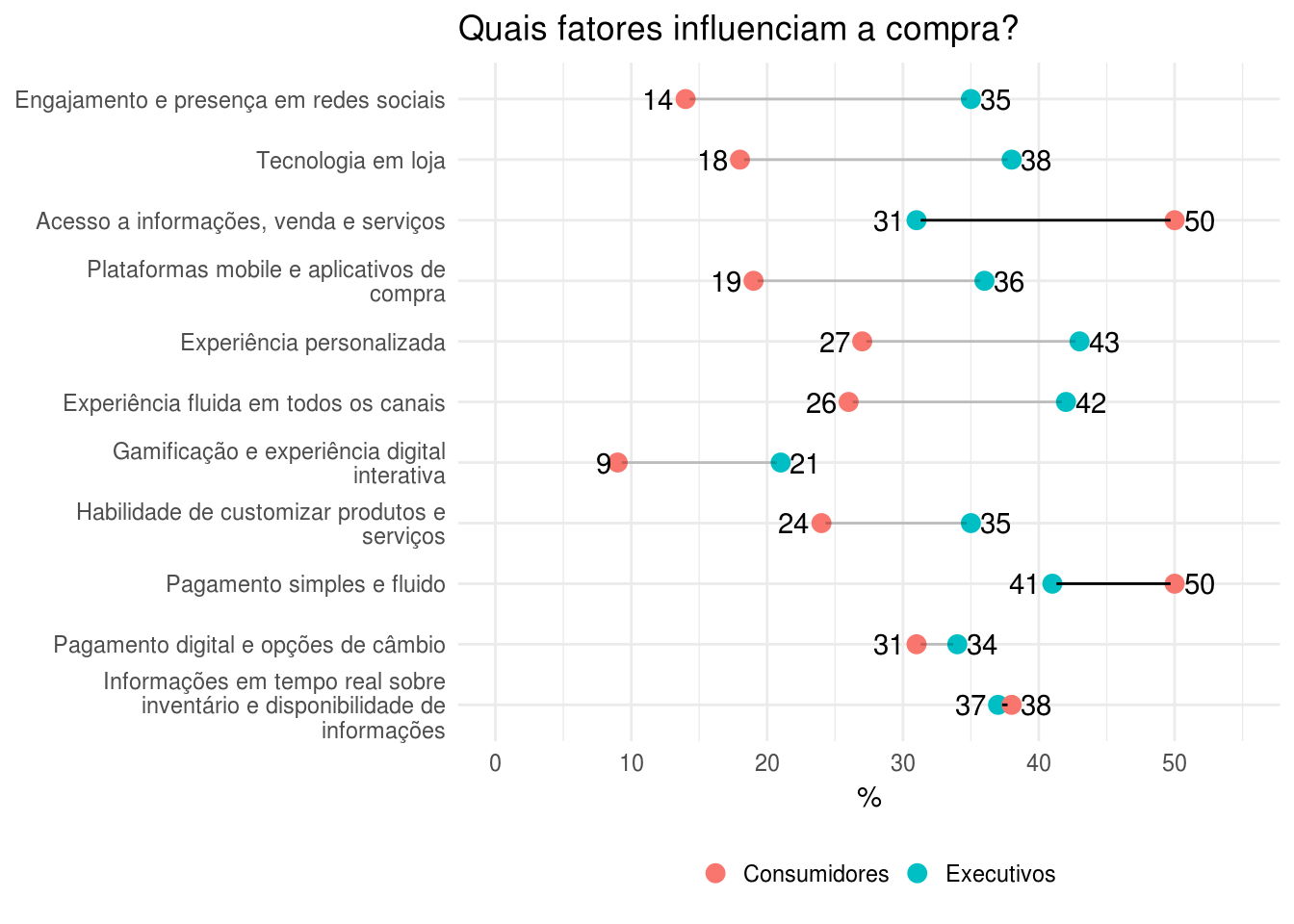
Acredito que, com essa visualização, as mensagens que o gráfico da revista foi criado para mostrar são transmitidas mais claramente.
comments powered by Disqus