No meu último post sobre Mineração de Texto, usei algumas ferramentas do R para analisar textos clássicos da literatura brasileira. Desta vez, o foco da análise será algo mais contemporâneo: uma youtuber. Mais precisamente, a Nathalia Arcuri, responsável por um dos principais canais de educação financeira, o Me Poupe.
Além do objeto da análise, a abordagem aqui também é diferente: vou mostrar como Topic Modeling pode ser usado para descobrir temas gerais em um conjunto de dados textuais.
Assim, este post se dedica ao seguinte problema de pesquisa: é possível identificar, por meio de um algoritmo de inteligência artificial, temas gerais que uma youtuber com mais de 300 vídeos publicados fala sobre?
library(reticulate)
reticulate::use_python("/home/sillas/anaconda3/bin/python", required = TRUE)
library(lexiconPT)
library(tidytext)
library(tidyverse)
library(magrittr)
library(stm)
library(tm)
library(ggridges)
library(formattable)
options(scipen = 999)Coleta dos dados
Para analisar o conteúdo de vídeos de youtube, precisamos das legendas dos vídeos. Alguns (bem poucos) canais produzem suas próprias legendas manualmente, mas a grande maioria, como o Me Poupe, o canal da Nathalia Arcuri, não o faz. Sendo assim, precisamos nós mesmo produzir essas legendas.
Isso seria uma tarefa muito árdua, mas felizmente o próprio Youtube tem seu próprio serviço de inteligência artifical de reconhecimento de fala, que cria automaticamente legendas para um vídeo. Apesar de algumas vezes as legendas produzidas pelo algoritmo do Youtube não serem muito fiéis, elas serão usadas como dados brutos para a modelagem por tópicos. Os resultados apresentados no post mostram que essas legendas automáticas podem sim serem usadas para fins de estudo.
Para coletar as legendas dos vídeo, eu uso um utilitário de linha de comando chamado youtube-dl, que é bem simples de usar. No código abaixo, que mistura R com shell script, eu mostro como montar uma query para baixar as legendas do vídeo em arquivos de texto cujos nomes contem alguns metadados do vídeo, descritos na variável fields_raw. Caso você deseje realizar este mesmo estudo com outro youtuber, basta atribuir a url do canal na variável channel_url.
fields_raw <- c("id", "title", "alt_title", "creator", "release_date",
"timestamp", "upload_date", "duration", "view_count",
"like_count", "dislike_count", "comment_count")
fields <- fields_raw %>%
map_chr(~paste0("%(", ., ")s")) %>%
# usar &&& como separador de fields
paste0(collapse = "&&&") %>%
# acrescentar aspas no inicio e no final do string
paste0('"', ., '"')
# canal do me poupe
channel_url <- "https://www.youtube.com/channel/UC8mDF5mWNGE-Kpfcvnn0bUg"
# montar query (comando) do youtube-dl
cmd_ytdl <- str_glue("youtube-dl -o {fields} -i -v -w --skip-download --write-auto-sub --sub-lang pt {channel_url}")
# acrescentar diretorio
pasta_captions <- "/home/sillas/R/Projetos/paixaopordados-blogdown/data/mepoupe"
fs::dir_create(pasta_captions)
cmd <- str_glue("cd {pasta_captions} && {cmd_ytdl}")
# imprimir comando para ver como ficou
cat(cmd)## cd /home/sillas/R/Projetos/paixaopordados-blogdown/data/mepoupe && youtube-dl -o "%(id)s&&&%(title)s&&&%(alt_title)s&&&%(creator)s&&&%(release_date)s&&&%(timestamp)s&&&%(upload_date)s&&&%(duration)s&&&%(view_count)s&&&%(like_count)s&&&%(dislike_count)s&&&%(comment_count)s" -i -v -w --skip-download --write-auto-sub --sub-lang pt https://www.youtube.com/channel/UC8mDF5mWNGE-Kpfcvnn0bUgPortanto, temos o comando para baixar as legendas dos vídeos na pasta indicada. Para rodar o comando, basta a variável cmd como argumento da função system() ou o copiar e colar no terminal.
Uma amostra dos arquivos baixados:
dir(pasta_captions)[1:3]## [1] "039orzgCUt0&&&10 DILEMAS MAIS FREQUENTES SOBRE TESOURO DIRETO! Tire as dúvidas e invista!&&&NA&&&NA&&&NA&&&NA&&&20170424&&&642&&&272848&&&33970&&&137&&&NA.pt.vtt"
## [2] "0bqZrSaitDo&&&PLANILHA DE INDEPENDÊNCIA FINANCEIRA! Aprenda a usar! Série especial_ Office 365 #AjudaaNath&&&NA&&&NA&&&NA&&&NA&&&20170328&&&988&&&260474&&&18439&&&206&&&NA.pt.vtt"
## [3] "0eSSqsHSr2A&&&Série empreendedorismo na veia Ep 3_ EXPERIENTES TAMBÉM FALHAM!&&&NA&&&NA&&&NA&&&NA&&&20161225&&&282&&&32361&&&2307&&&21&&&NA.pt.vtt"Limpeza dos dados
O Youtube tem um formato próprio de arquivos para legendas chamado vtt. Veja como são os arquivos de texto baixados na etapa anterior:
arquivos_captions <- dir(pasta_captions, pattern = '*.vtt', full.names = TRUE)
amostra <- arquivos_captions[1]
read_lines(amostra)[1:30]## [1] "WEBVTT"
## [2] "Kind: captions"
## [3] "Language: pt"
## [4] "Style:"
## [5] "::cue(c.colorCCCCCC) { color: rgb(204,204,204);"
## [6] " }"
## [7] "::cue(c.colorE5E5E5) { color: rgb(229,229,229);"
## [8] " }"
## [9] "##"
## [10] ""
## [11] "00:00:00.000 --> 00:00:02.419 align:start position:0%"
## [12] " "
## [13] "olha<00:00:00.329><c> o</c><00:00:00.420><c> data</c><c.colorE5E5E5><00:00:00.840><c> mtow</c><00:00:01.260><c> que</c><00:00:01.350><c> apurou</c><00:00:01.709><c> que</c><00:00:01.979><c> esta</c></c>"
## [14] ""
## [15] "00:00:02.419 --> 00:00:02.429 align:start position:0%"
## [16] "olha o data<c.colorE5E5E5> mtow que apurou que esta"
## [17] " </c>"
## [18] ""
## [19] "00:00:02.429 --> 00:00:04.640 align:start position:0%"
## [20] "olha o data<c.colorE5E5E5> mtow que apurou que esta</c>"
## [21] "<c.colorCCCCCC>pergunta</c><c.colorE5E5E5><00:00:03.210><c> este</c><00:00:03.389><c> dilema</c><00:00:03.780><c> é</c><00:00:04.170><c> o</c><00:00:04.259><c> mais</c></c>"
## [22] ""
## [23] "00:00:04.640 --> 00:00:04.650 align:start position:0%"
## [24] "<c.colorCCCCCC>pergunta</c><c.colorE5E5E5> este dilema é o mais"
## [25] " </c>"
## [26] ""
## [27] "00:00:04.650 --> 00:00:06.650 align:start position:0%"
## [28] "<c.colorCCCCCC>pergunta</c><c.colorE5E5E5> este dilema é o mais</c>"
## [29] "<c.colorE5E5E5>freqüente<00:00:05.190><c> de</c><00:00:05.310><c> tudo</c><00:00:05.700><c> o</c><00:00:05.790><c> que</c></c><c.colorCCCCCC><00:00:05.970><c> investiu</c><00:00:06.509><c> uma</c></c>"
## [30] ""Temos vários problemas de dados não estruturados aí, como timestamps, formatação de estilo como cor e alinhamento e repetição de frases em diferentes linhas (note como as frases nas linhas 24 e 28 são as mesmas). Entretanto, limpar esses dados é mais simples que se imagina. Segue o passo-a-passo:
Começando pelo mais crítico, vamos remover toda a formatação de legendas do texto, deixando apenas as frases. Para isso, uso um módulo Python (sim, eu me rendi, esta é a primeira vez que uso Python no blog) chamado webvtt:
from webvtt import WebVTT
def caption_to_vector(file):
x = WebVTT().read(file)
txt = [caption.text for caption in x]
return(txt)Vejam com essa função faz todo o trabalho bruto de limpar os metadados da legenda:
x <- amostra %>% caption_to_vector()
x[1:20]## [1] " \nolha o data mtow que apurou que esta"
## [2] "olha o data mtow que apurou que esta\n "
## [3] "olha o data mtow que apurou que esta\npergunta este dilema é o mais"
## [4] "pergunta este dilema é o mais\n "
## [5] "pergunta este dilema é o mais\nfreqüente de tudo o que investiu uma"
## [6] "freqüente de tudo o que investiu uma\n "
## [7] "freqüente de tudo o que investiu uma\nvez só ou possa investir todo mês"
## [8] "vez só ou possa investir todo mês\n "
## [9] "vez só ou possa investir todo mês\nfilho olha esse aqui se não ficar nos"
## [10] "filho olha esse aqui se não ficar nos\n "
## [11] "filho olha esse aqui se não ficar nos\nvídeos em alta do yuan subir é"
## [12] "vídeos em alta do yuan subir é\n "
## [13] "vídeos em alta do yuan subir é\nmarmelada hoje vou falar para você"
## [14] "marmelada hoje vou falar para você\n "
## [15] "marmelada hoje vou falar para você\nquais são os dez maiores dilemas de"
## [16] "quais são os dez maiores dilemas de\n "
## [17] "quais são os dez maiores dilemas de\nquem quer investir no tesouro direto mas"
## [18] "quem quer investir no tesouro direto mas\n "
## [19] "quem quer investir no tesouro direto mas\nainda não sabe muito bem como fazer"
## [20] "ainda não sabe muito bem como fazer\n "Ainda temos alguns problemas, como as linhas repetidas, mas isso é o de menos. Resolvemos todos os problemas de limpeza de dados com a função abaixo:
limpar_caption <- function(arquivo){
caption_raw <- caption_to_vector(arquivo)
n <- length(caption_raw)
# remover \n das linhas com exceção da ultima
caption <- c(stringr::str_remove_all(caption_raw[-n], "[\n].*"),
caption_raw[n])
# remover duplicatas
caption <- unique(caption)
# remover acentos
caption <- iconv(caption, from = "UTF-8", to = "ASCII//TRANSLIT")
# juntar todo o vector em um so
caption <- paste0(caption, collapse = "\n")
caption
}
# exemplo
# amostra %>% limpar_caption()Além disso, precisamos também extrair os metadados dos vídeos salvos nos nomes dos arquivos:
# funcao para extrair metadados do video baseado no titulo
extrair_metadados <- function(arquivo, pasta = pasta_captions,
fields = fields_raw){
mat <- str_split(arquivo, "&{3}", simplify = TRUE)
# substituir elemento da primeira coluna por id (remover pasta do nome)
mat[1,1] <- mat[1,1] %>% str_remove_all(pasta) %>% str_remove_all("/")
# renomear colunas
cols <- fields[1:ncol(mat)]
colnames(mat) <- cols
as.tibble(mat)
}Finalmente, a função abaixo cria um dataframe com as colunas de metadados e de legenda, que chamo de caption:
# funcao para juntar tudo num dataframe so
caption_to_df <- function(arquivo, ...){
caption <- limpar_caption(arquivo)
meta <- extrair_metadados(arquivo, ...)
meta <- meta %>% mutate(caption = caption)
meta
}
### gerar dataframe para todos os videos
df <- arquivos_captions %>%
map_df(caption_to_df) %>%
# remover coluna que nao uso
select(-comment_count) %>%
# converter a classe de algumas colunas
mutate(upload_date = lubridate::ymd(upload_date)) %>%
mutate_at(vars(duration:dislike_count), as.numeric)
# vendo como ficou
glimpse(df)## Observations: 319
## Variables: 12
## $ id <chr> "039orzgCUt0", "0bqZrSaitDo", "0eSSqsHSr2A", "0G...
## $ title <chr> "10 DILEMAS MAIS FREQUENTES SOBRE TESOURO DIRETO...
## $ alt_title <chr> "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", ...
## $ creator <chr> "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", ...
## $ release_date <chr> "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", ...
## $ timestamp <chr> "NA", "NA", "NA", "NA", "NA", "NA", "NA", "NA", ...
## $ upload_date <date> 2017-04-24, 2017-03-28, 2016-12-25, 2016-02-15,...
## $ duration <dbl> 642, 988, 282, 440, 670, 647, 574, 396, 615, 614...
## $ view_count <dbl> 272848, 260474, 32361, 242366, 262462, 53146, 11...
## $ like_count <dbl> 33970, 18439, 2307, 13163, 14439, 3868, 9369, 17...
## $ dislike_count <dbl> 137, 206, 21, 371, 453, 89, 110, 176, 87, 149, 1...
## $ caption <chr> " \nolha o data mtow que apurou que esta\npergun...Topic Modeling
Antes de partir para o código aplicado a Topic Modeling, uma brevíssima introdução teórica.
No contexto de Text Mining, um tópico \(T\) é definido como um conjunto de palavras ou tokens (\(w_1, w_2, ... w_n\)) onde cada palavra possui uma probabilidade de pertencer a um tópico, e um documento é definido como um conjunto de tópicos, onde cada um possui uma proporção de presença dentro do documento. A soma da proporção de cada tópico dentro de um documento é igual a 1, assim como a soma das probabilidades de cada palavra para um dado tópico, que também é igual a 1. Nesta análise, um documento corresponde a cada vídeo lançado no canal Me Poupe.
Topic Modeling, portanto, é definido como uma ténica não-supervisionada de Machine Learning que busca que identica clusteres ou grupos de palavras que ocorrem juntas, descobrindo assim tópicos abstratos que ocorrem em um conjunto de documentos. O objetivo é descobrir subestruturas semânticas dentro de um conjunto de textos.
Existem alguns algoritmos de Topic Modeling, muitos deles presentes no pacote topicmodels. Apenas devido a preferência pessoal, vou usar neste post o algoritmo Structural Topic Models (STM), presente no pacote stm.
A qualidade de um tópico encontrado por um algoritmo pode ser medida por algumas métricas, como exclusividade e coerência semântica, cuja ideia é que, em um modelo de tópicos que é semanticamente coerente, as palavras que são mais prováveis de pertencer a um tópico devem ocorrer dentro de um mesmo documento. A formulação matemática dessas métricas é razoavelmente mais complicadas que essas explicações. Caso você deseja conhecer essas métricas com mais detalhes, confira as referências no final do post.
Pré-processamento
Mesmo após o processo de limpeza, é necessário realizar alguns pré-processamentos antes de aplicar o algoritmo de Topic Modeling.
Um dos procedimentos necessários é a remoção de stopwords, que são palavras que ocorrem tão frequentemente que não acrescentam nenhum valor semântico a um texto, como “e”, “vai”, “lá”, etc. O pacote tm fornece uma lista de stopwords em vários idiomas, incluindo Português.
O código abaixo retorna as palavras mais faladas nos vídeos do Me Poupe, após a remoção de stopwords:
# stopwords da lingua portuguesa sem acento
sw_pt_tm <- tm::stopwords("pt") %>% iconv(from = "UTF-8", to = "ASCII//TRANSLIT")
# criar dataframe com uma linha por palavra
df_palavra <- df %>%
unnest_tokens(palavra, caption) %>%
# filtrar fora stopword
filter(!palavra %in% sw_pt_tm)
df_palavra %>%
count(palavra) %>%
arrange(desc(n)) %>%
head(20) %>%
formattable()| palavra | n |
|---|---|
| vai | 5467 |
| gente | 3297 |
| porque | 3077 |
| aqui | 3047 |
| pra | 3001 |
| dinheiro | 2731 |
| fazer | 2373 |
| entao | 2256 |
| pode | 2119 |
| la | 2097 |
| ter | 1645 |
| ai | 1614 |
| agora | 1520 |
| ser | 1516 |
| pessoas | 1354 |
| canal | 1334 |
| vou | 1334 |
| hoje | 1319 |
| video | 1267 |
| tudo | 1243 |
Como muitas dessas palavras não possuem um grande valor semântico para a separação de tópicos, podemos as acrescentar à lista de stopwords.
minhas_sw <- c("vai", "porque", "vou", "ai", "pra", "entao")
sw_pt <- c(minhas_sw, sw_pt_tm)Partimos então para o processamento de textos com as funções do pacote stm.
proc <- stm::textProcessor(df$caption, metadata = df, language = "portuguese",
customstopwords = sw_pt)## Building corpus...
## Converting to Lower Case...
## Removing punctuation...
## Removing stopwords...
## Remove Custom Stopwords...
## Removing numbers...
## Stemming...
## Creating Output...out <- stm::prepDocuments(proc$documents, proc$vocab, proc$meta,
lower.thresh = 10)## Removing 14665 of 16857 terms (33357 of 129408 tokens) due to frequency
## Your corpus now has 319 documents, 2192 terms and 96051 tokens.Criação do modelo de tópicos e interpretação dos resultados
A quantidade de tópicos \(K\) que desejamos extrair dos textos é, na verdade, escolhida pelo ser humano. Não há uma regra precisa que defina o número ótimo de clusteres. No entanto, é possível usar a função stm::searchK para rodar o STM para diferentes valores do parâmetro K para encontrar o valor que otimiza a exclusividade e a coerência semântica do modelo.
storage <- stm::searchK(out$documents, out$vocab, K = c(3:15),
data = out$meta)Após uma inspeção manual, decidi usar \(K = 10\) para encontrar 10 tópicos sobre os quais a Nathalia Arcuri mais fala.
fit <- stm(
documents = out$documents, vocab = out$vocab, data = out$meta, K = 10,
max.em.its = 75, init.type = "Spectral", verbose = FALSE
)Após a construção do modelo, a melhor forma de visualizar os resultados é por meio de um gráfico:
plot(fit, "summary")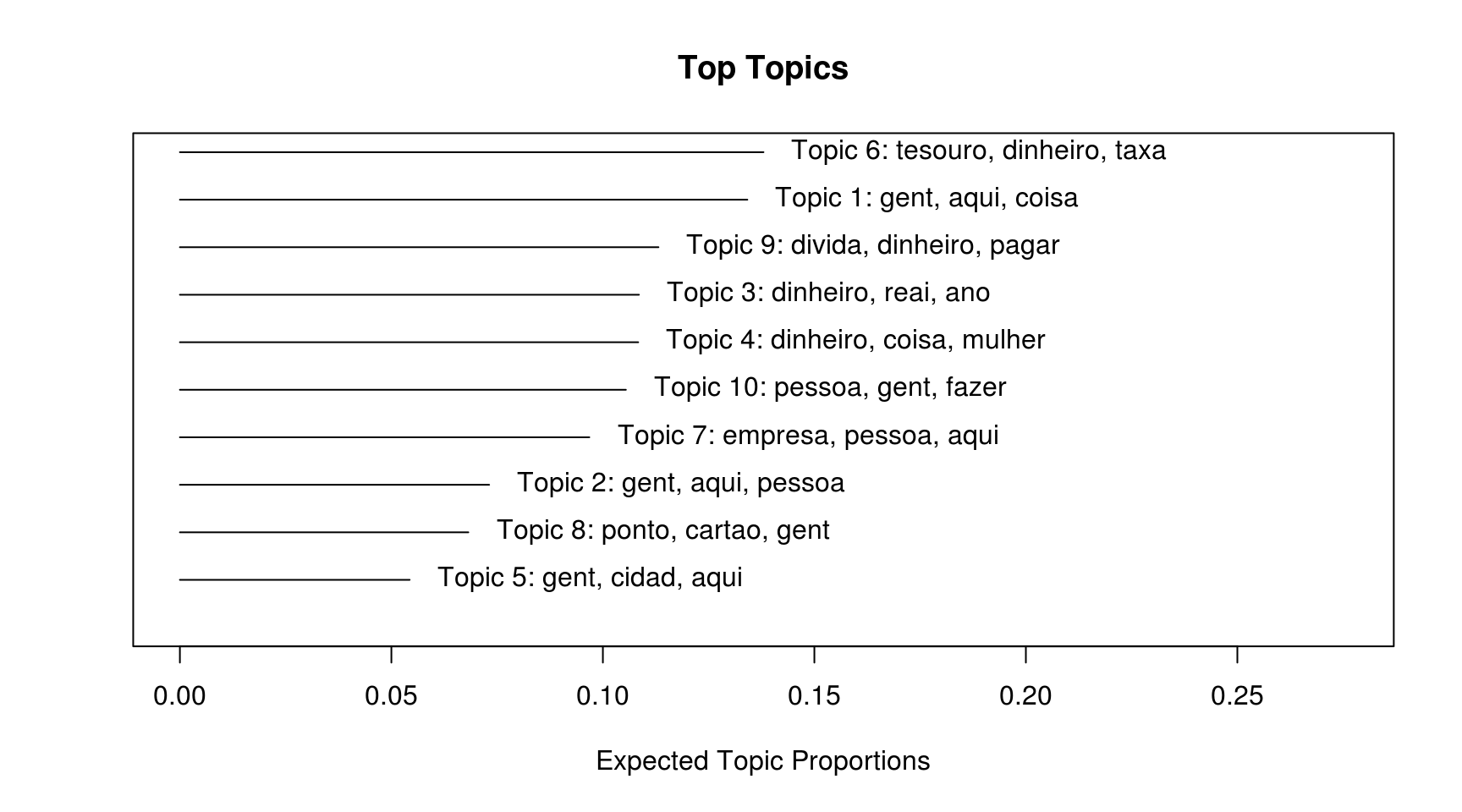
Ou mesmo por texto:
stm::labelTopics(fit)## Topic 1 Top Words:
## Highest Prob: gent, aqui, coisa, fazer, pode, assim, casa
## FREX: roupa, cabelo, peca, barato, economizar, comer, loja
## Lift: energia, cor, tratamento, sapato, ovo, armario, compro
## Score: energia, tratamento, ovo, cabelo, pared, loja, dica
## Topic 2 Top Words:
## Highest Prob: gent, aqui, pessoa, pergunta, agora, vamo, fazer
## FREX: milhao, hashtag, galera, pergunta, poup, job, inscrito
## Lift: bilhao, premio, jornalista, seguidor, contrata, hashtag, orgulho
## Score: bilhao, live, job, milhao, premio, hashtag, conteudo
## Topic 3 Top Words:
## Highest Prob: dinheiro, reai, ano, aqui, fazer, video, mil
## FREX: meta, planilha, tarefa, viver, aposentadoria, reai, poupar
## Lift: vitoria, offic, aposentar, caderno, planilha, metodo, produtividad
## Score: vitoria, caderno, meta, offic, planilha, joaquina, metodo
## Topic 4 Top Words:
## Highest Prob: dinheiro, coisa, mulher, vida, pessoa, pode, ser
## FREX: mulher, mae, present, crianca, casamento, maravilha, pai
## Lift: gostam, casamento, adulto, maravilha, honesto, casar, present
## Score: gostam, casamento, natal, present, maravilha, adulto, objetivo
## Topic 5 Top Words:
## Highest Prob: gent, cidad, aqui, rio, janeiro, fazer, candidato
## FREX: cidad, candidato, prefeitura, janeiro, rio, prefeito, municipio
## Lift: arrecadou, evasiva, habitacao, municipio, prefeitura, promovida, tocar
## Score: municipio, tocar, candidato, prefeitura, habitacao, corrupcao, prefeito
## Topic 6 Top Words:
## Highest Prob: tesouro, dinheiro, taxa, fundo, direto, aqui, investimento
## FREX: tesouro, selic, fundo, direto, taxa, titulo, corretora
## Lift: digit, garantidor, imobiliario, ipc, ipc-, cdi, tesouro
## Score: digit, tesouro, selic, imobiliario, corretora, taxa, rentabilidad
## Topic 7 Top Words:
## Highest Prob: empresa, pessoa, aqui, pode, fazer, dinheiro, valor
## FREX: aco, aplicativo, empresa, aluguel, mercado, bolsa, acao
## Lift: placa, aco, lucro, bolo, alugar, documento, moeda
## Score: placa, aco, investidor, alugar, bolo, empresa, lucro
## Topic 8 Top Words:
## Highest Prob: ponto, cartao, gent, credito, aqui, pode, fazer
## FREX: multiplus, ponto, acumular, multiplo, cartao, black, site
## Lift: milha, anuidad, multiplus, multiplo, passagen, acumular, acumula
## Score: multiplus, anuidad, multiplo, ponto, black, acumular, cartao
## Topic 9 Top Words:
## Highest Prob: divida, dinheiro, pagar, carro, credito, cartao, pode
## FREX: divida, carro, parcela, pagar, juro, credito, ajuda
## Lift: chequ, financiado, quitar, devendo, divida, parcelar, parcela
## Score: chequ, divida, credito, cartao, financiamento, parcela, consorcio
## Topic 10 Top Words:
## Highest Prob: pessoa, gent, fazer, ser, aqui, dinheiro, ter
## FREX: ingl, empreendedor, curso, faculdad, sucesso, segredo, negocio
## Lift: encontrei, mestr, ingl, atividad, consequencia, tecnico, milionaria
## Score: encontrei, live, faculdad, empreendedor, conteudo, ingl, chefeNa tabela acima, existe para cada tópico uma lista de palavras-chave, de acordo com uma métrica de associação. As métricas mais interessantes a serem olhadas são Highest prob, que é basicamente uma contagem de cada palavra no tópico, e FREX, que é combina frequência e exclusividade para identificar palavras que mais representam o tópico.
Assim, a interpretação dos tópicos pode ser feita desta maneira:
- Tópico 1: Dicas de economia doméstica, como que para reduzir despesas em casa;
- Tópico 2: Genérico;
- Tópico 3: Planejamento Financeiro, com temas como planilhas e aposentadoria;
- Tópico 4: Vídeos focados para mulheres ou famílias;
- Tópico 5: Política;
- Tópico 6: Renda Fixa (este ficou bem claro);
- Tópico 7: Dificil saber. Talvez renda variável;
- Tópico 8: Cartão de cŕedito e temas afins, como programas de milhas;
- Tópico 9: Dívidas e despesas;
- Tópico 10: Empreendedorimo.
É possível representar visualmente a diferença entre um par de tópicos, como o 6 e o 9:
plot(fit, "perspective", topics = c(9, 6))
Percebe-se que as palavras “dívida” e “tesouro” separam bem esses dois tópicos.
Atribuição de tópicos a vídeos
Um dos possíveis produtos da análise de Topic Modeling é atribuir a cada documento (ou vídeo) um tópico, de acordo com a proporção de cada tópico nele.
O objeto fit possui internamente um elemento que é uma matriz \(N \times K\), onde N é o número de documentos. Assim, para cada vídeo, existe um porcentual de participação de cada tópico, cuja soma é igual a 1.
Vejamos essa matriz para os cinco primeiros vídeos:
head(fit$theta)## [,1] [,2] [,3] [,4] [,5]
## [1,] 0.000273920 0.003253428 0.004040834 0.0009959664 0.0001388210
## [2,] 0.018310800 0.030741680 0.708967915 0.0118358411 0.0006963748
## [3,] 0.070843633 0.041732621 0.013845361 0.0304166112 0.0839133871
## [4,] 0.008194601 0.002381194 0.008008110 0.0033322595 0.0018488345
## [5,] 0.010782705 0.026464694 0.010263833 0.0477243086 0.1095574639
## [6,] 0.006023939 0.872040010 0.005714869 0.0059672704 0.0481083479
## [,6] [,7] [,8] [,9] [,10]
## [1,] 0.985509536 0.002881037 0.0001246733 0.002037421 0.0007443629
## [2,] 0.183050228 0.005301315 0.0292175603 0.008811973 0.0030663133
## [3,] 0.010378165 0.176350442 0.0412429834 0.262069287 0.2692075093
## [4,] 0.001888864 0.106774265 0.8546355488 0.011153510 0.0017828124
## [5,] 0.047119628 0.504319587 0.0113556114 0.156215296 0.0761968712
## [6,] 0.019619518 0.011139023 0.0019899886 0.006333920 0.0230631152Observando a primeira linha, nota-se que existe um claro predomínio do Tópico 6, que representa 98% da distribuição de tópicos. Qual é esse vídeo?
df %>%
filter(row_number() == 1) %>%
select(id, title)## # A tibble: 1 x 2
## id title
## <chr> <chr>
## 1 039orzgCUt0 10 DILEMAS MAIS FREQUENTES SOBRE TESOURO DIRETO! Tire as dú…Vemos que o algoritmo acertou na mosca, pois de fato o vídeo é sobre Renda Fixa.
A qual tópico pertence o vídeo mais assistido do Me Poupe?
# id do video Meu Primeiro Milhao
ind <- which(df$id == "4jaWDfTbytA")
t(fit$theta[ind,])## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 0.05483404 0.03399528 0.5101044 0.01345342 0.0007212358 0.003021568
## [,7] [,8] [,9] [,10]
## [1,] 0.003167582 0.001051847 0.003699136 0.3759515Os tópicos predominantes são 3 (Planejamento financeiro), com probabilidade de 51% e 10 (empreendedorismo), com 38%. Faz sentido, porque neste vídeo a Nathalia conta sua história como empreendedora para atingir seu primeiro milhão por meio de muito planejamento financeiro (não tô forçando, eu vi o vídeo).
Vamos então, para cada vídeo, extrair seu tópico predominante e contar a frequência de videos por tópico:
nomes_topicos <- c("economia_domestica", "generico", "plan_financeiro",
"mulher_familia", "politica", "renda_fixa", "renda_variavel",
"cartao_de_credito", "dividas", "empreendedorismo")
# extrair a maior probabilidade pra cada video
maior_prob <- apply(fit$theta, 1, max)
# extrair o nome do topico com a maior probabilidade
topico_video <- nomes_topicos[apply(fit$theta, 1, which.max)]
# acrescentar esses dados no dataframe principal
df_topico <- df %>%
mutate(maior_prob = maior_prob,
topico = topico_video)roxo <- "mediumpurple4"
# grafico da quantidade de videos por topico
df_topico %>%
count(topico) %>%
# classificar em ordem decrescente
mutate(topico = forcats::fct_reorder(topico, n)) %>%
ggplot(aes(x = topico, y = n)) +
geom_col(fill = roxo) +
theme_minimal() +
labs(x = NULL, y = "Vídeos",
title = "Quantidade de vídeos por tópico") +
coord_flip()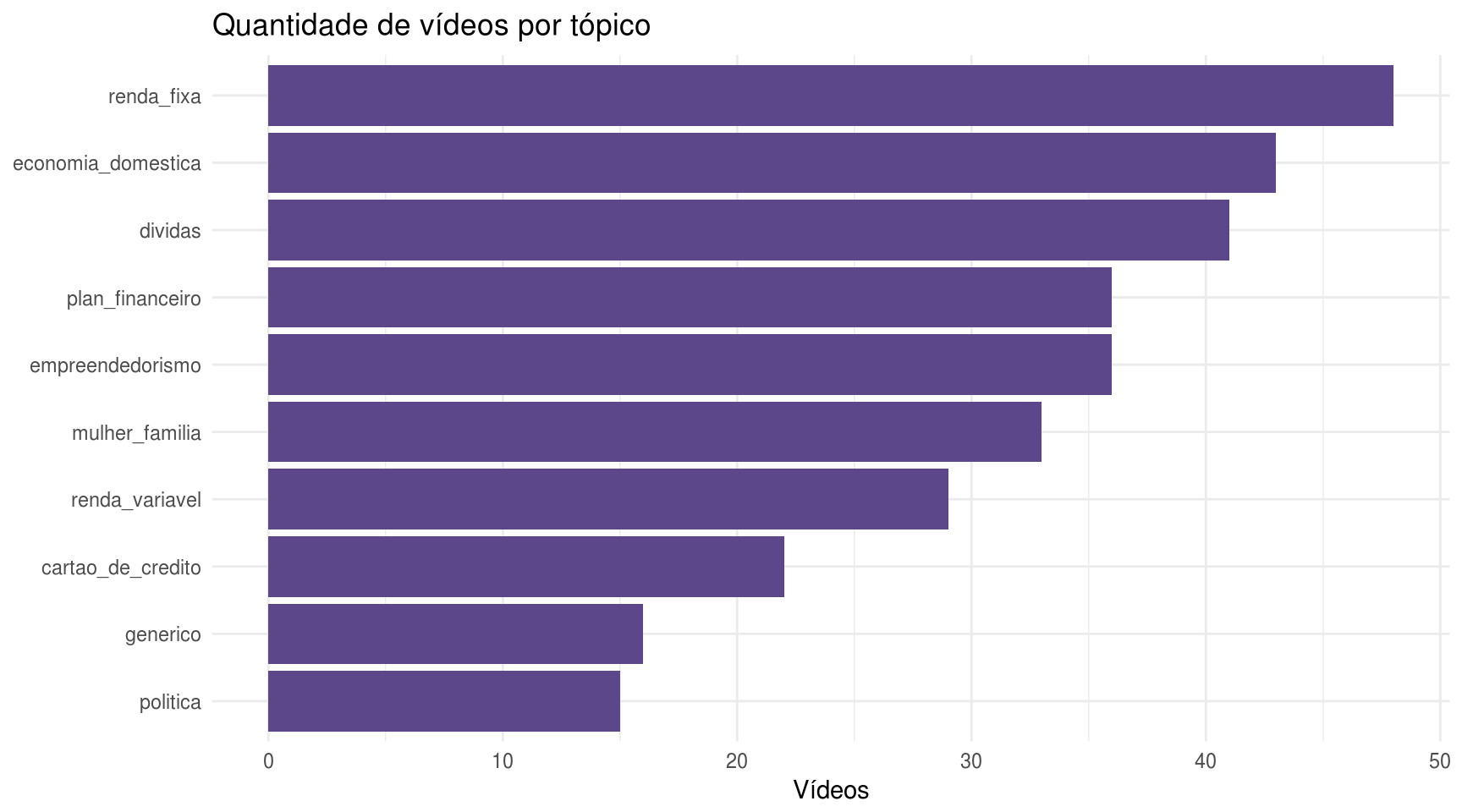
Os tópicos sobre os quais a Nathalia mais fala são Renda Fixa, Economia Doméstica e Dívidas. Quem acompanha seu canal não vai ficar surpreso com estes resultados, o que é um índicio da qualidade do modelo construído neste post.
Também é possível extrair os vídeos chaves de cada tópico, isto é, os vídeos com a maior probabilidade para cada tópico:
df_topico %>%
group_by(topico) %>%
filter(maior_prob == max(maior_prob)) %>%
select(id, title, topico, maior_prob) %>%
knitr::kable()| id | title | topico | maior_prob |
|---|---|---|---|
| _alsKxI3-TI | NATH AO VIVO! COMO VIAJAR SEM COLOCAR A MÃO NO BOLSO! Dicas preciosas dos viciados por pontos! | cartao_de_credito | 0.9906875 |
| eMQZRHoIgtQ | COMO EU TIRO AS METAS DO PAPEL! Técnica simples pra juntar mais dinheiro do que nunca! | plan_financeiro | 0.9773071 |
| FHqHW8-xvLQ | Dia das crianças - COMO FALAR QUE A GRANA TÁ CURTA | mulher_familia | 0.9717965 |
| iA9Iqx2uByo | Entrevista - Carlos Osório - Que Candidato é esse | politica | 0.9907593 |
| kddZm50Gluw | Perguntas e respostas #5 - Cartão de crédito e FIM DE NAMORO! | dividas | 0.9629534 |
| liIQENCBlF0 | SE VOCÊ NÃO ENTENDER ISSO, NUNCA VAI INVESTIR NA BOLSA!_ Renda variável do jeito mais simples | renda_variavel | 0.9695903 |
| R0AQyTIvcvI | O que é SELIC E CDI Entenda isso HOJE e pare de PERDER DINHEIRO! _ SÉRIE INVESTIDORES INICIANTES | renda_fixa | 0.9899924 |
| SfG934AzjYU | COMO EU COMPRO ROUPAS DUAS VEZES AO ANO! Episódio final _ A negociação! | economia_domestica | 0.9877744 |
| WtFV03Suheg | A FINAL DA CONTRATAÇÃO QUE VOCÊ RESPEITA! Quem a Nath vai contratar (AGORA GRAVADO) | generico | 0.9605720 |
| Zla1-t3aOZw | 3 ESCOLHAS QUE ENRIQUECERAM O CERBASI _ meu guru | empreendedorismo | 0.9151230 |
Eu, pessoalmente, estou bastante satisfeito com os resultados. A modelagem de tópicos funcionou muito bem.
Vamos estão analisar algumas estatísticas básicas para cada tópico: quais têm os vídeos mais longos? Quais são os mais populares?
meu_grafico <- function(df, var){
quo_var <- enquo(var)
mediana_geral <- df %>%
summarise_at(vars(!!quo_var), median, na.rm = TRUE) %>%
pull()
# obter grafico
p <- df %>%
group_by(topico) %>%
summarise(m = median(!!quo_var, na.rm = TRUE)) %>%
ggplot(aes(x = topico, y = m)) +
geom_col(fill = roxo) +
geom_hline(yintercept = mediana_geral, linetype = "dashed") +
theme_minimal() +
coord_flip() +
labs(x = NULL, y = NULL)
p
}
meu_grafico(df_topico, duration) + ggtitle("Média da duração dos vídeos por tópico do Me Poupe")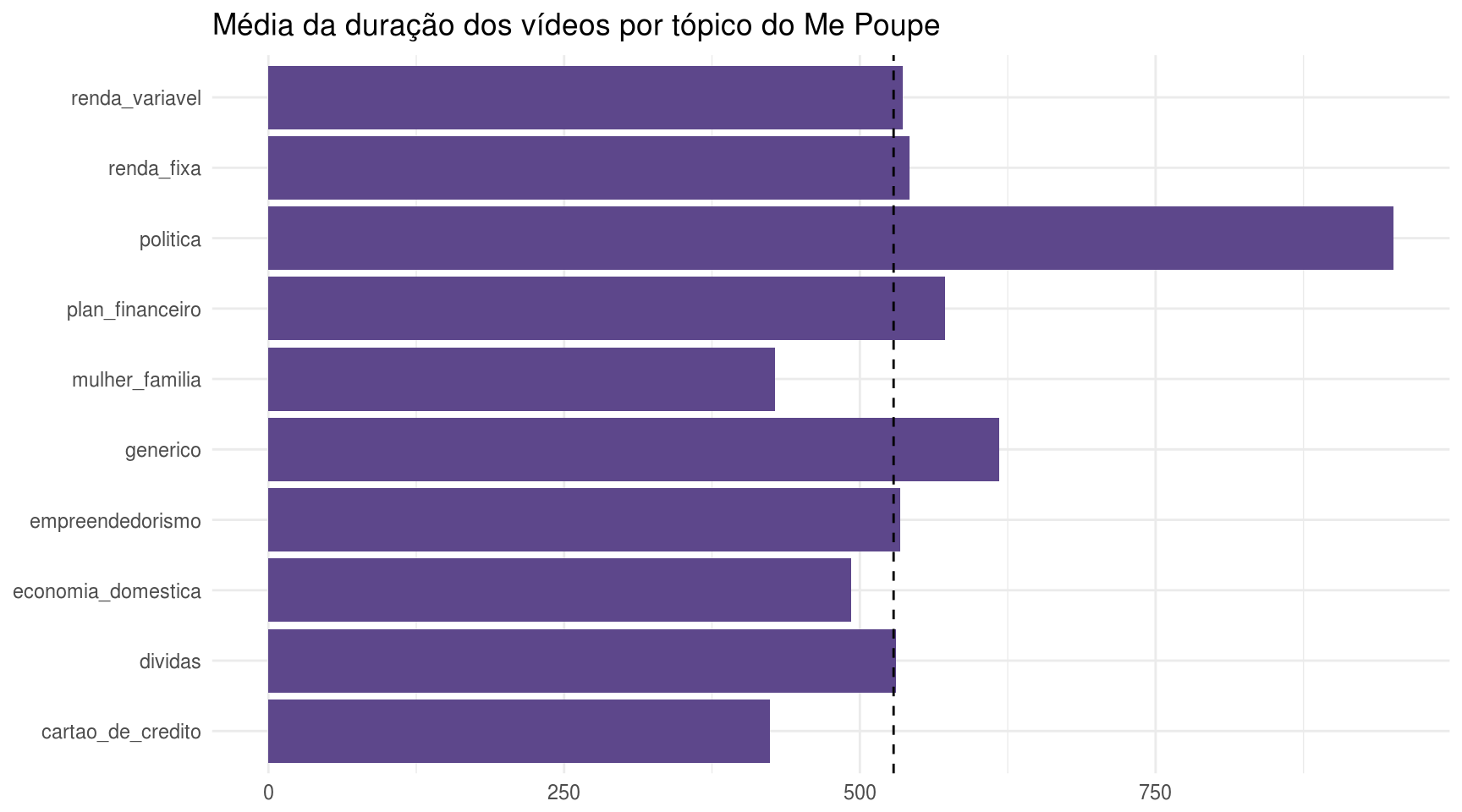
meu_grafico(df_topico, view_count) + ggtitle("Média de views por tópico do Me Poupe")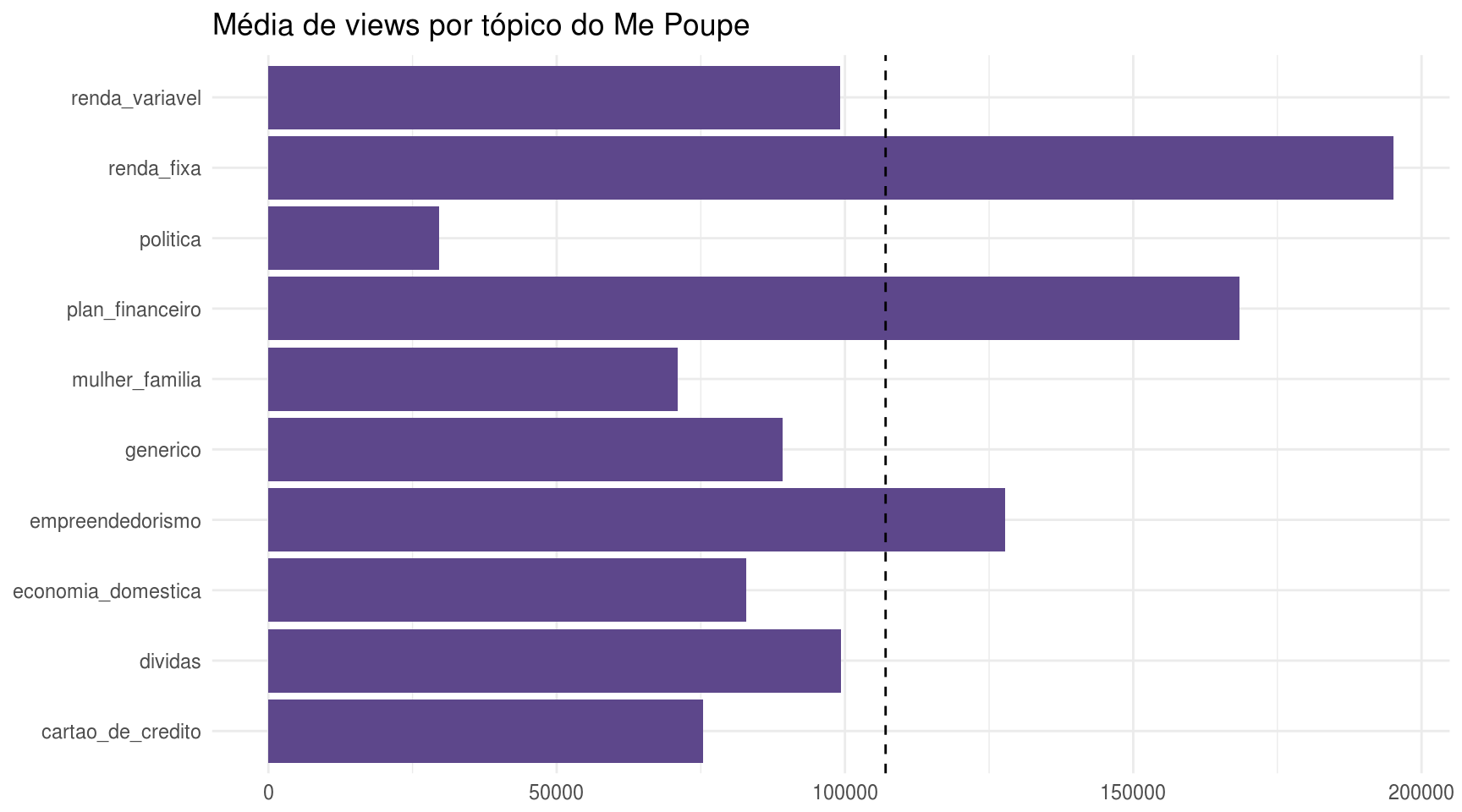
meu_grafico(df_topico, like_count) + ggtitle("Média de likes por tópico do Me Poupe")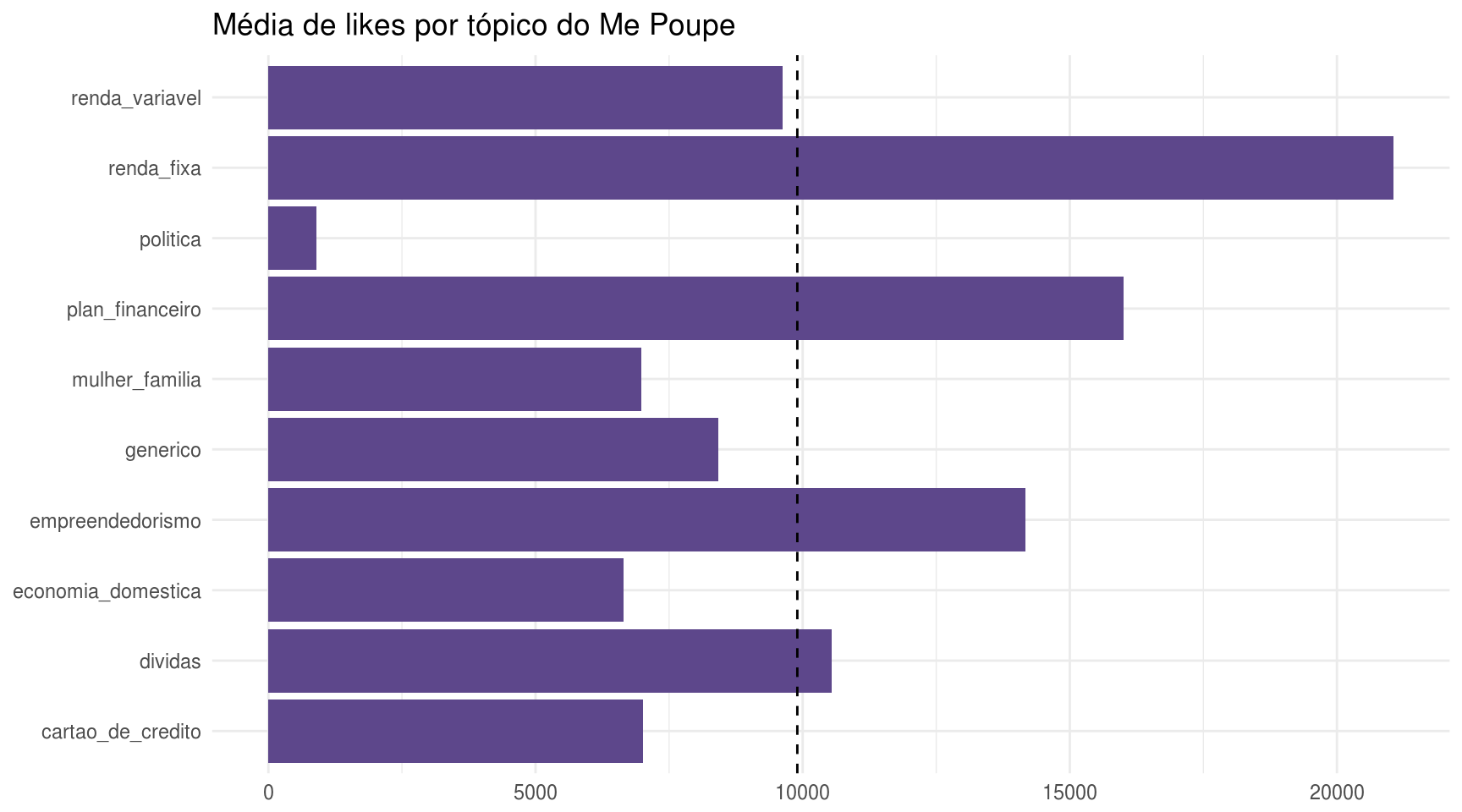
Com estes gráficos, aprendemos que os vídeos sobre renda fixa, planejamento financeiro e empreendedorismo são os mais populares entre os “me poupeiros” (como a Nathalia chama quem acompanha o canal), pois possuem mais visualizações e curtidas. Outro fato interessante é que os vídeos categorizados como política são, por assim dizer, improdutivos, pois, apesar de serem os mais longos, possuem muitos poucos views. Existem alguns possíveis tipos de viés que poderiam explicar este dado, como o temporal.
Análise de Sentimento
Finalmente, vamos aplicar uma abordagem de análise de sentimento para analisar se os tópicos apresentam diferentes polaridades entre si. Quais tópicos são mais negativos?
data("sentiLex_lem_PT02")
dict <- unique(sentiLex_lem_PT02)
# criacao do dataframe de sentimento por topico
df_sent <- df %>%
unnest_tokens(palavra, caption) %>%
inner_join(sentiLex_lem_PT02, by = c("palavra" = "term")) %>%
group_by(id) %>%
summarise(
sentimento_soma = sum(polarity),
sentimento_media = mean(polarity)
)
# acrescentar ao dafaframe principal
df_topico_sent <- inner_join(df_topico, df_sent, by = "id")
# calcular sentimento geral dos videos
sent_medio_geral <- median(df_topico_sent$sentimento_media)
df_topico_sent %>%
mutate(topico = forcats::fct_reorder(topico, sentimento_media, median)) %>%
ggplot(aes(x = sentimento_media, y = topico)) +
geom_density_ridges(fill = roxo) +
geom_vline(xintercept = sent_medio_geral, linetype = "dashed") +
theme_minimal() +
labs(x = "Sentimento", y = NULL,
title = "Distribuição dos sentimentos por tópico do Me Poupe")## Picking joint bandwidth of 0.0756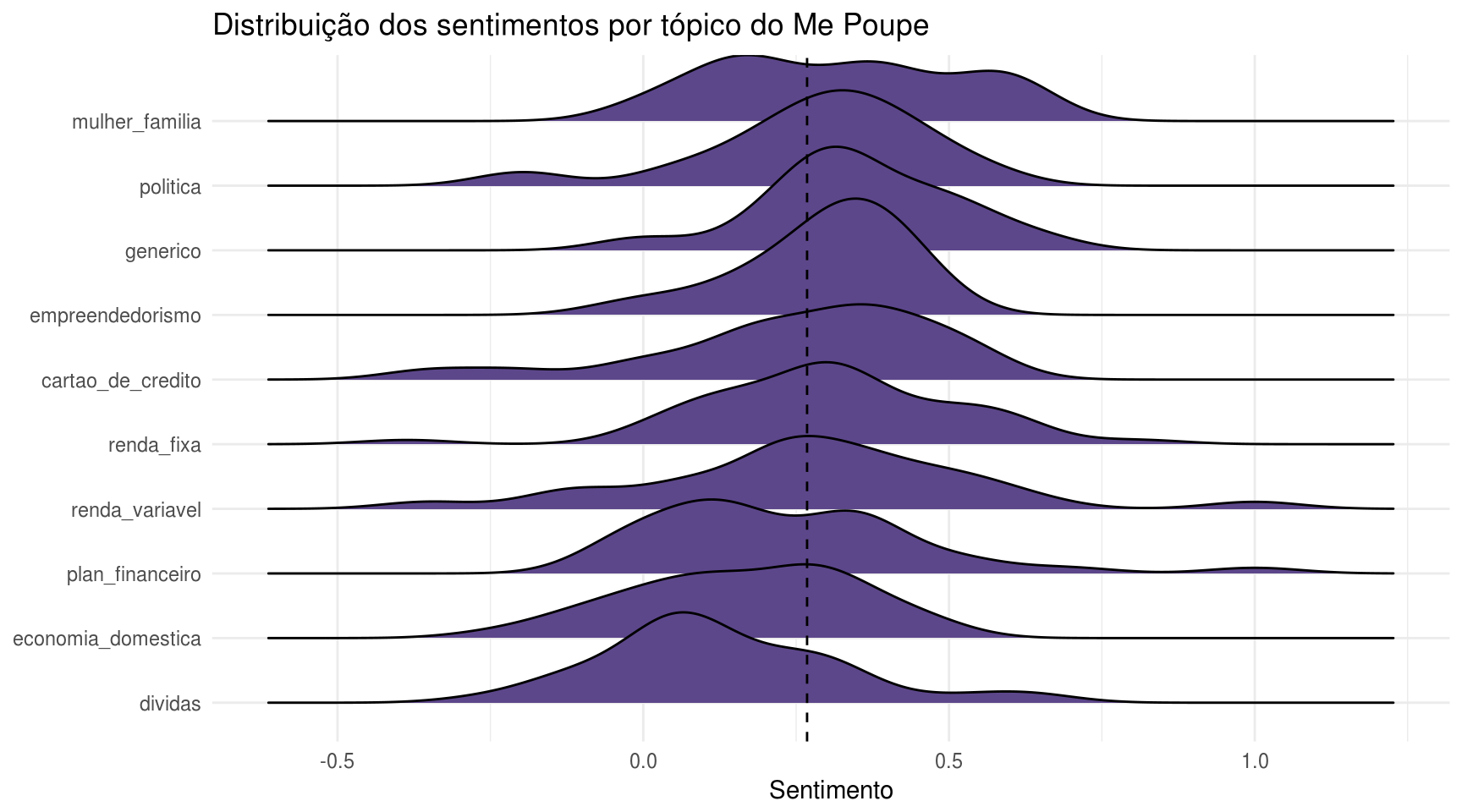
Em novamente o que eu considero um acerto da metodologia, os vídeos de dívidas apresentaram polaridades mais baixas, ou sejas, um nível de sentimento mais negativo.
Conclusão
É relativamente difícil avaliar a acurácia e precisão de um algoritmo de topic modeling por essa técnica ser não-supervisionada, ou seja, os dados não possuírem um output com a resposta correta.
Contudo, os resultados apresentados neste post mostram que é possível sim usar esse tipo de técnica, com um certo auxílio de interpretação humana, para categorizar um conjunto de vídeos sem ser necessário os assistir ou mesmo sem saber seus títulos.
Referências
Antes das referências formais, gostaria de indicar o post do Júlio Trecenti, que é um outro exemplo de uso criativo de análise de dados para youtubers.
https://en.wikipedia.org/wiki/Topic_model
Mimno, D., Wallach, H. M., Talley, E., Leenders, M., & McCallum, A. (2011, July). “Optimizing semantic coherence in topic models.” In Proceedings of the Conference on Empirical Methods in Natural Language Processing (pp. 262-272). Association for Computational Linguistics. Chicago
Roberts, M., Stewart, B., Tingley, D., Lucas, C., Leder-Luis, J., Gadarian, S., Albertson, B., et al. (2014). “Structural topic models for open ended survey responses.” American Journal of Political Science, 58(4), 1064-1082
Margaret E. Roberts, Brandon M. Stewart and Dustin Tingley (2018). stm: R Package for Structural Topic Models. URL http://www.structuraltopicmodel.com.