Módulo 4 Outros tipos de gráficos
Pacotes deste módulo:
# importar pacotes
# install.packages(c("plotly", "sf", "ggmap", "sunburstR", "leaflet", "treemap"))
# devtools::install_github("italocegatta/brmap")
library(tidyverse)
library(plotly)
library(sf)
library(ggmap)
library(sunburstR)
library(leaflet)
library(treemap)
library(brmap)Continuaremos alguns datasets usados nos módulos anteriores:
# importar datasets
# indice de felicidade
df_feliz <- read_rds("dados_felicidade_2017.rds")
# dados econômicos
df_series <- read_rds("series_ipca_selic.rds")4.1 Transformando gráficos do ggplot2 em interativos
É possível ainda dar ainda mais vida aos seus gráficos os transformando em interativos de maneira muito fácil. O pacote plotly, além de ser um ótimo pacote para produzir gráficos interativos em R ou Python, possui uma funcão chamada ggplotly() que transforma um gráfico estático do ggplot2 em interativo.
Vamos recriar um dos gráficos construídos anteriormente, salvar em um objeto e o transformar em interativo:
# grafico do pib per capita em funcao da expectativa de vida
p <- df_feliz %>%
ggplot(aes(x = healthy_life_expectancy_at_birth, y = log_gdp_per_capita)) +
geom_point(aes(color = continent)) +
geom_smooth(method = "lm") +
theme_minimal()
# converter para interativo
ggplotly(p)
Com apenas uma simples função, temos um gráfico cheio de recursos interativos, como possibilidade de dar zoom em áreas específicos do gráfico e tooltips, que é a pequena tabela de dados que aparece na tela ao passar o mouse em um ponto ou na reta criada por geom_smooth().
Como era de se esperar, as tooltips também podem ser customizadas. A função ggplotly possui um parâmetro chamado tooltip onde pode ser especificada a aesthetic que será mostrada na tooltip. Por padrão, como você viu, a tooltip mostra todas as aesthetics definidas no gráfico. Caso você queira mudar esse aspecto, pode mudar o valor desse parâmetro em ggplotly:
# mostrar apenas a aesthetic x,
# na qual foi mapeada a variavel de expectativa de vida
ggplotly(p, tooltip = "x")Incrivelmente, dá para ficar ainda melhor. É definindo uma nova aesthetic chamada text, que por padrão não pertence ao ggplot2 mas é usada pelo plotly para construir a tooltip.
Essa nova aesthetic, usada em combinação com a função paste0, pode criar tooltips informativas e elegantes.
Caso não conheça a função paste0(), ela serve para concatenar vetores de strings em um só, de maneira paralelizada.
Segue alguns exemplos:
nome <- c("Lucas", "Eduardo", "Flávio")
sobrenome <- c("Silva", "Oliveira", "Dias")
# concatenar os dois vetores acima, juntando nome e sobrenome com espaço no meio
paste0(nome, " ", sobrenome)## [1] "Lucas Silva" "Eduardo Oliveira" "Flávio Dias"Usando essa função, vamos definir a aesthetic de forma que mostre o nome dos países e os valores das variáveis dos eixos:
# refazer o grafico, definindo uma nova aesthetic chamada text:
p <- df_feliz %>%
ggplot(aes(x = healthy_life_expectancy_at_birth, y = log_gdp_per_capita)) +
geom_point(aes(color = continent,
text = paste0(country,
healthy_life_expectancy_at_birth,
log_gdp_per_capita)
)) +
geom_smooth(method = "lm") +
theme_minimal()
ggplotly(p, tooltip = "text")Passe o mouse nos pontos e veja o resultado. Note que foi possível incluir a variável do nome do país no gráfico, mesmo não estando definida em nenhuma aesthetic além de text.
Contudo, a tooltip não ficou muito visualmente agradável, correto? Isso porque ficou tudo em uma linha só. Felizmente, é possível fazer melhor usando a função paste0 ao nosso favor (Lembre-se que \n é um caracter especial do R que serve para quebrar linhas):
p <- df_feliz %>%
ggplot(aes(x = healthy_life_expectancy_at_birth, y = log_gdp_per_capita)) +
geom_point(aes(color = continent,
text = paste0(
"País: ", country, "\n",
"Expec. vida: ", round(healthy_life_expectancy_at_birth, 0), "\n",
"PIB per capita (log): " , round(log_gdp_per_capita, 2)
))) +
geom_smooth(method = "lm") +
theme_minimal()
ggplotly(p, tooltip = "text")4.1.1 Salvando um gráfico ggplotly
Para salvar um gráfico produzido pelo plotly, basta salvar em um objeto e usar a função saveWidget, do pacote htmlwidgets, que é instalado junto com o plotly. O gráfico deve ser salvo com a extensão html e pode ser aberto usando um browser, como o Firefox.
p_interativo <- ggplotly(p, tooltip = "text")
# salve
htmlwidgets::saveWidget(p_interativo, "meu_grafico_interativo.html")Referências:
Site do pacote plotly
4.2 Mapas: plotando polígonos
Produzir mapas com o R nunca foi tão fácil como hoje, graças a avanços recentes dos pacotes sf e ggplot2. Foge muito do escopo deste curso explicar a estrutura de dados espaciais, como shapefiles. Mesmo sem esse entedimento, porém, é possível fazer gráficos com mapas de maneira muito simples.
O pacote brmap, desenvolvido pelo brasileiro Ítalo Cegatta, facilita a importação de arquivos shapefiles fornecidos no site do IBGE. Existem shapefiles para municípios (brmap_municipio), estados (brmap_estado), regiões (brmap_regiao) e o país (brmap_brasil).
# importar o shp de estados
data(brmap_estado)
head(brmap_estado)## Simple feature collection with 6 features and 4 fields
## geometry type: POLYGON
## dimension: XY
## bbox: xmin: -73.99045 ymin: -13.6937 xmax: -46.07095 ymax: 5.271841
## epsg (SRID): 4674
## proj4string: +proj=longlat +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +no_defs
## # A tibble: 6 x 5
## cod_regiao cod_estado estado_nome estado_sigla geometry
## <int> <int> <chr> <chr> <POLYGON [°]>
## 1 1 11 Rondônia RO ((-62.86662 -7.975868, -…
## 2 1 12 Acre AC ((-73.18253 -7.335496, -…
## 3 1 13 Amazonas AM ((-67.32609 2.029714, -6…
## 4 1 14 Roraima RR ((-60.20051 5.264343, -6…
## 5 1 15 Pará PA ((-54.95431 2.583692, -5…
## 6 1 16 Amapá AP ((-51.1797 4.000081, -51…Observe que o dataframe possui quatro colunas, sendo a última relacionada às informações espaciais sobre os polígonos dos estados que serão usadas para construir os mapas.
A sintaxe do ggplot2 para construir mapas é relativamente diferente: não é preciso definir nenhuma aesthetic, pois a função geom_sf internamente busca a coluna de polígonos presente no objeto:
ggplot(brmap_estado) +
# a linha abaixo da no mesmo que geom_sf(aes(geometry = geometry))
geom_sf()
A partir do gráfico base criado acima, as customizações seguem o padrão do ggplot2. Por exemplo, é possível mapear a cor os polígonos de acordo com uma variável presente nos dados, além de alterar aspectos visuais com a função theme:
ggplot(brmap_estado) +
# a linha abaixo da no mesmo que geom_sf(aes(geometry = geometry))
geom_sf(aes(geometry = geometry,
# colorir os poligonos de acordo com sua regiao
fill = as.character(cod_regiao))) +
# deixar o mapa mais limpo e sem eixos
theme(
panel.background = element_blank(),
panel.grid.major = element_line(color = "transparent"),
axis.text = element_blank(),
axis.ticks = element_blank()
) +
# mudar titulo da legenda
labs(fill = "Região")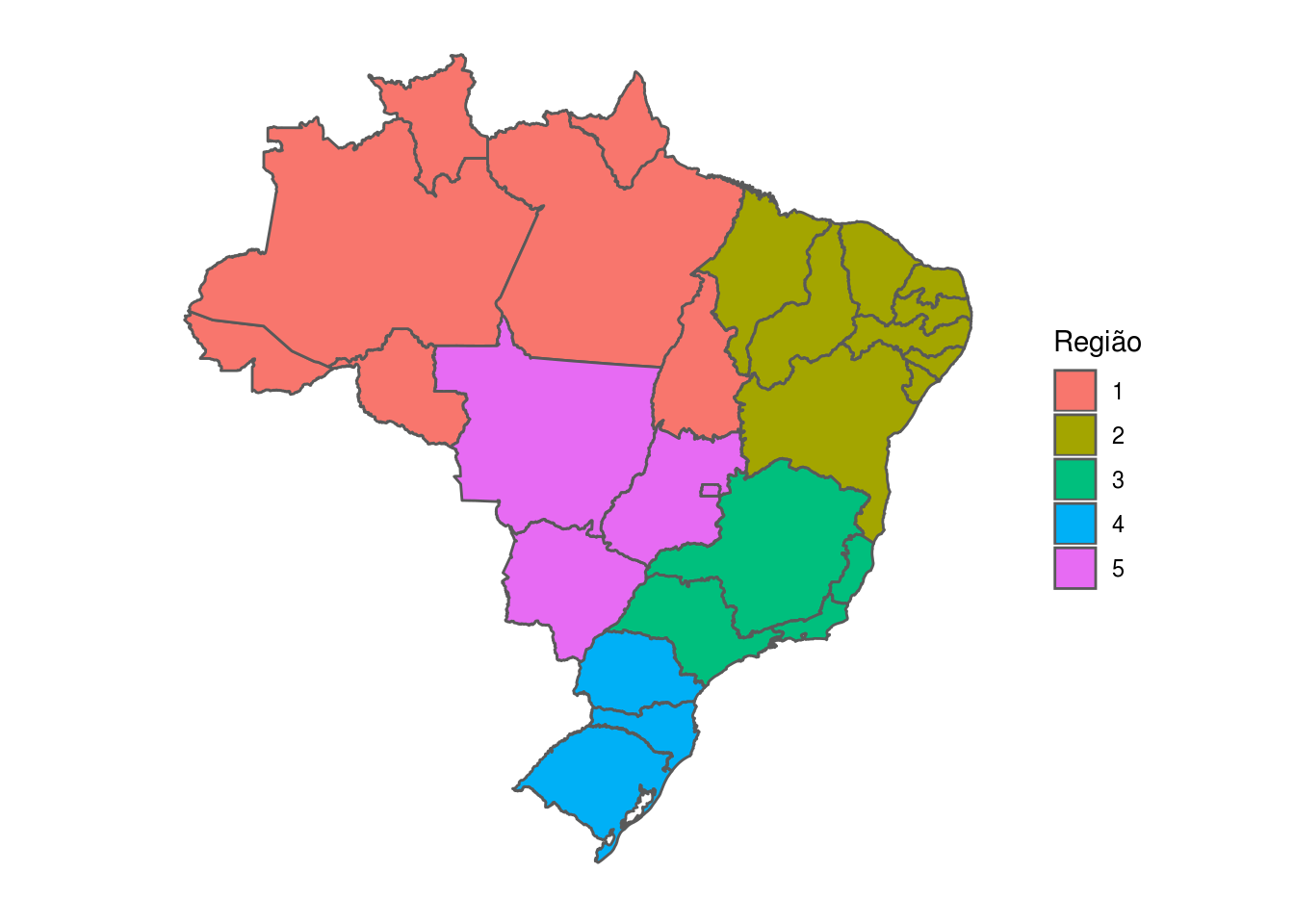
Referências:
geom_sf()
Tutorial de geom_sf()
4.2.1 Projeto: plotando o resultado do segundo turno das eleições para presidente de 2014 por UF:
Neste exemplo, mostramos como o ggplot2 pode ser usado para produzir mapas muito informativos, mapeando a cor de cada polígono a uma variável numérica, como PIB ou população. Neste caso, usamos dados eleitorais das eleições para Presidência da República no segundo turno de 2014, vencida pelo PT contra o PSDB.
Observe o passo-a-passo de coleta e transformação dos dados das eleições:
# baixar dados do TSE de votação por municipio e zona
link <- "http://agencia.tse.jus.br/estatistica/sead/odsele/votacao_partido_munzona/votacao_partido_munzona_2014.zip"
download.file(link, destfile = "tse.zip")
# descompactar arquivo
unzip("tse.zip")# definir vetor com nomes das colunas
cols <- c("DATA_GERACAO", "HORA_GERACAO", "ANO_ELEICAO", "NUM_TURNO",
"DESCRICAO_ELEICAO", "SIGLA_UF", "SIGLA_UE", "CODIGO_MUNICIPIO",
"NOME_MUNICIPIO", "NUMERO_ZONA", "CODIGO_CARGO", "DESCRICAO_CARGO",
"TIPO_LEGENDA", "NOME_COLIGACAO", "COMPOSICAO_LEGENDA",
"SIGLA_PARTIDO", "NUMERO_PARTIDO", "NOME_PARTIDO",
"QTD_VOTOS_NOMINAIS", "QTD_VOTOS_LEGENDA", "TRANSITO")
# conveter para minusculo
cols <- str_to_lower(cols)
# definir encoding
lcl <- locale(encoding = "ISO-8859-1")
# ler arquivo
eleicoes <- read_csv2("/home/sillas/R/data/eleicoes_2014/votacao_partido_munzona_2014/votacao_partido_munzona_2014_BR.txt",
col_names = FALSE,
locale = lcl,
progress = FALSE) %>%
# remover ultima coluna
select(-22) %>%
# mudar nome das colunas
set_names(cols)
head(eleicoes)## # A tibble: 6 x 21
## data_geracao hora_geracao ano_eleicao num_turno descricao_eleic… sigla_uf
## <chr> <time> <int> <int> <chr> <chr>
## 1 17/05/2018 04:15 2014 2 Eleições Gerais… PB
## 2 17/05/2018 04:15 2014 2 Eleições Gerais… PR
## 3 17/05/2018 04:15 2014 2 Eleições Gerais… PR
## 4 17/05/2018 04:15 2014 2 Eleições Gerais… RS
## 5 17/05/2018 04:15 2014 2 Eleições Gerais… MT
## 6 17/05/2018 04:15 2014 2 Eleições Gerais… PB
## # ... with 15 more variables: sigla_ue <chr>, codigo_municipio <chr>,
## # nome_municipio <chr>, numero_zona <int>, codigo_cargo <int>,
## # descricao_cargo <chr>, tipo_legenda <chr>, nome_coligacao <chr>,
## # composicao_legenda <chr>, sigla_partido <chr>, numero_partido <int>,
## # nome_partido <chr>, qtd_votos_nominais <int>, qtd_votos_legenda <int>,
## # transito <chr>A partir do arquivo importado, iremos agregar os dados por estado e calcular a quantidade de votos para PT e PSDB:
eleicoes_agg <- eleicoes %>%
filter(ano_eleicao == 2014, num_turno == 2, descricao_cargo == "Presidente") %>%
# agrupar por UF e partido
group_by(sigla_uf, sigla_partido) %>%
summarise(qtd_votos = sum(qtd_votos_nominais)) %>%
# converter para formato wide
spread(sigla_partido, qtd_votos, fill = 0) %>%
# criar coluna chamada prop_PT, que representa o percentual de votos
# para o PT em todos os votos validos no estado
mutate(prop_PT = PT/(PT + PSDB))
head(eleicoes_agg)## # A tibble: 6 x 4
## # Groups: sigla_uf [6]
## sigla_uf PSDB PT prop_PT
## <chr> <dbl> <dbl> <dbl>
## 1 AC 243677 138982 0.363
## 2 AL 574322 941445 0.621
## 3 AM 556545 1033457 0.650
## 4 AP 142780 227509 0.614
## 5 BA 2153111 5059860 0.701
## 6 CE 1068169 3522884 0.767Com o dataframe de votos criado, podemos o unir com o dataframe que contem os dados espaciais dos estados:
estados_eleicoes <- left_join(brmap_estado,
eleicoes_agg,
by = c("estado_sigla" = "sigla_uf"))
head(estados_eleicoes)## Simple feature collection with 6 features and 7 fields
## geometry type: POLYGON
## dimension: XY
## bbox: xmin: -73.99045 ymin: -13.6937 xmax: -46.07095 ymax: 5.271841
## epsg (SRID): 4674
## proj4string: +proj=longlat +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +no_defs
## # A tibble: 6 x 8
## cod_regiao cod_estado estado_nome estado_sigla PSDB PT prop_PT
## <int> <int> <chr> <chr> <dbl> <dbl> <dbl>
## 1 1 11 Rondônia RO 4.43e5 3.64e5 0.451
## 2 1 12 Acre AC 2.44e5 1.39e5 0.363
## 3 1 13 Amazonas AM 5.57e5 1.03e6 0.650
## 4 1 14 Roraima RR 1.40e5 9.74e4 0.411
## 5 1 15 Pará PA 1.56e6 2.10e6 0.574
## 6 1 16 Amapá AP 1.43e5 2.28e5 0.614
## # ... with 1 more variable: geometry <POLYGON [°]>Enfim, podemos proceder com a criação do mapa:
ggplot(estados_eleicoes) +
geom_sf(aes(fill = prop_PT)) +
# mudar escala de cores para sequencial vermelha
scale_fill_distiller(type = "seq",
palette = "Reds",
direction = 1) +
# deixar o mapa mais limpo e sem eixos
theme(
legend.position = "bottom",
panel.background = element_blank(),
panel.grid.major = element_line(color = "transparent"),
axis.text = element_blank(),
axis.ticks = element_blank()
) +
labs(title = "Proporção de votos válidos para o PT por estado",
fill = NULL)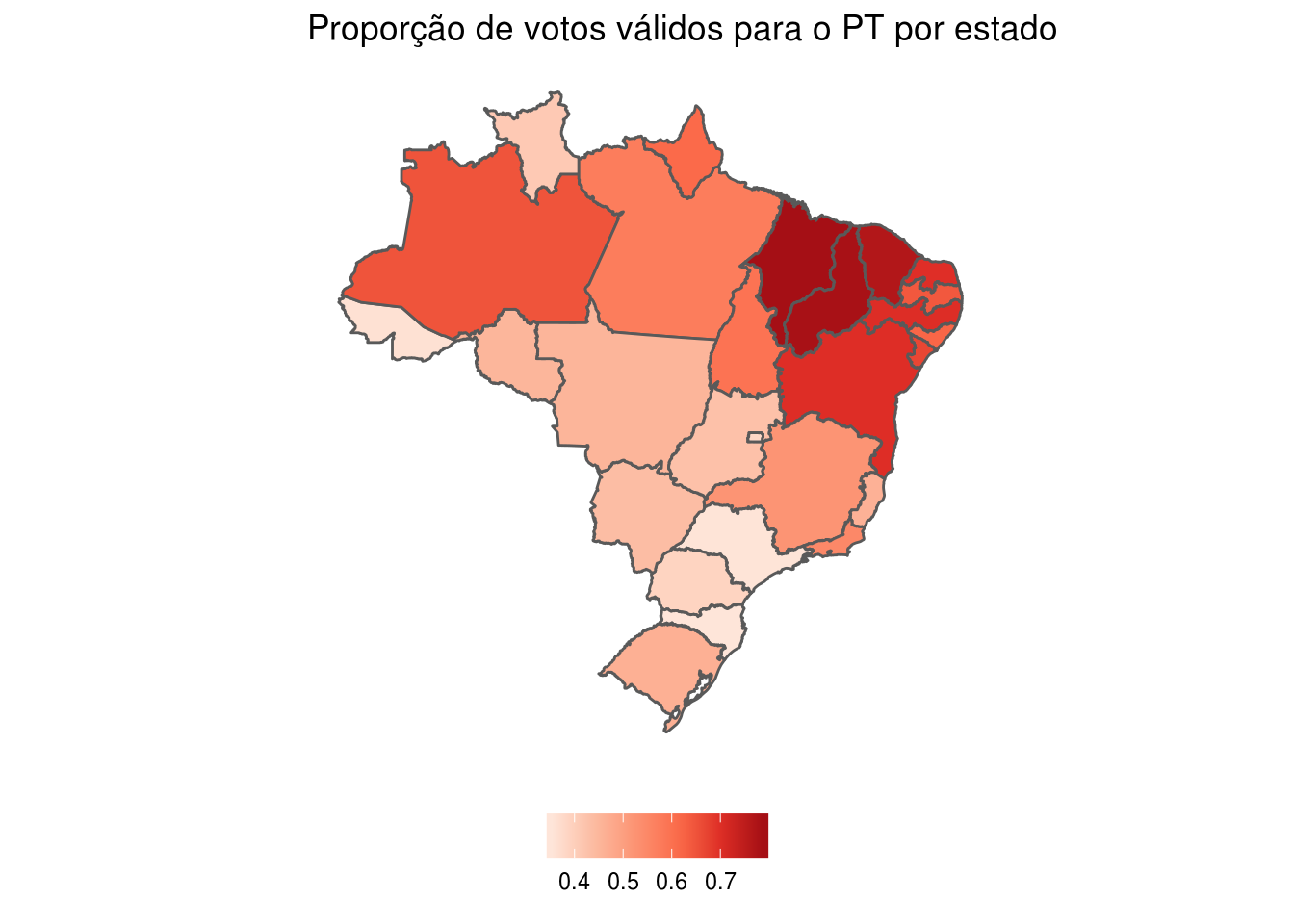
4.3 Mapas interativos
O pacote leaflet permite que criemos mapas com recursos interativos, com uma sintaxe um pouco diferente da do ggplot2 e ggmaps, porém usando também a sintaxe de camadas.
Um mapa básico do leaflet é criado com a seguinte sintaxe:
leaflet() %>%
addTiles()A função leaflet() inicializa o objeto e addTiles() cria uma camada de mapa. Para adicionar pontos a um mapa, basta usar a função addCirleMarkers():
paleta_cores <- colorFactor(c("blue", "red"),
unique(orcamento_sp$pa))
leaflet() %>%
addTiles() %>%
addCircleMarkers(
# definir o dataframe de referencia
data = orcamento_sp,
# usa-se uma sintaxe especial marcada pelo acento til seguido do nome da variavel
lng = ~longitude, lat = ~latitude,
# adicionar um popup
popup = ~ds_fonte,
color = ~paleta_cores(pa)
)4.4 Gráficos de dados hierárquicos: treemaps e sunburst
Para um tipo de dados específicos, os hierárquicos, treemaps e sunbursts são ótimas opções de visualização.
Suponha que você esteja analisando o seu orçamento pessoal, cujos dados são:
orcamento_pessoal <- tribble(
~nivel1, ~nivel2, ~nivel3, ~despesa,
"Moradia", "Aluguel", NA, 1300,
"Moradia", "Condominio", NA, 800,
"Mercado", "Alimentação", "Carnes", 150,
"Mercado", "Alimentação", "Vegetais", 50,
"Mercado", "Mat. de limpeza e higiene", NA, 100,
"Transp", "Carro", NA, 400,
"Transp", "Publico", NA, 150,
"Contas", "Energia", NA, 130,
"Contas", "Agua", NA, 60,
"Contas", "Netflix", NA, 27.90,
"Contas", "Internet", NA, 80,
"Lazer", "Restaurantes", NA, 350,
"Lazer", "Cultura", "Cinema", 100,
"Lazer", "Cultura", "Teatro", 50,
"Lazer", "Cultura", "Livros", 90
)
head(orcamento_pessoal)## # A tibble: 6 x 4
## nivel1 nivel2 nivel3 despesa
## <chr> <chr> <chr> <dbl>
## 1 Moradia Aluguel <NA> 1300
## 2 Moradia Condominio <NA> 800
## 3 Mercado Alimentação Carnes 150
## 4 Mercado Alimentação Vegetais 50
## 5 Mercado Mat. de limpeza e higiene <NA> 100
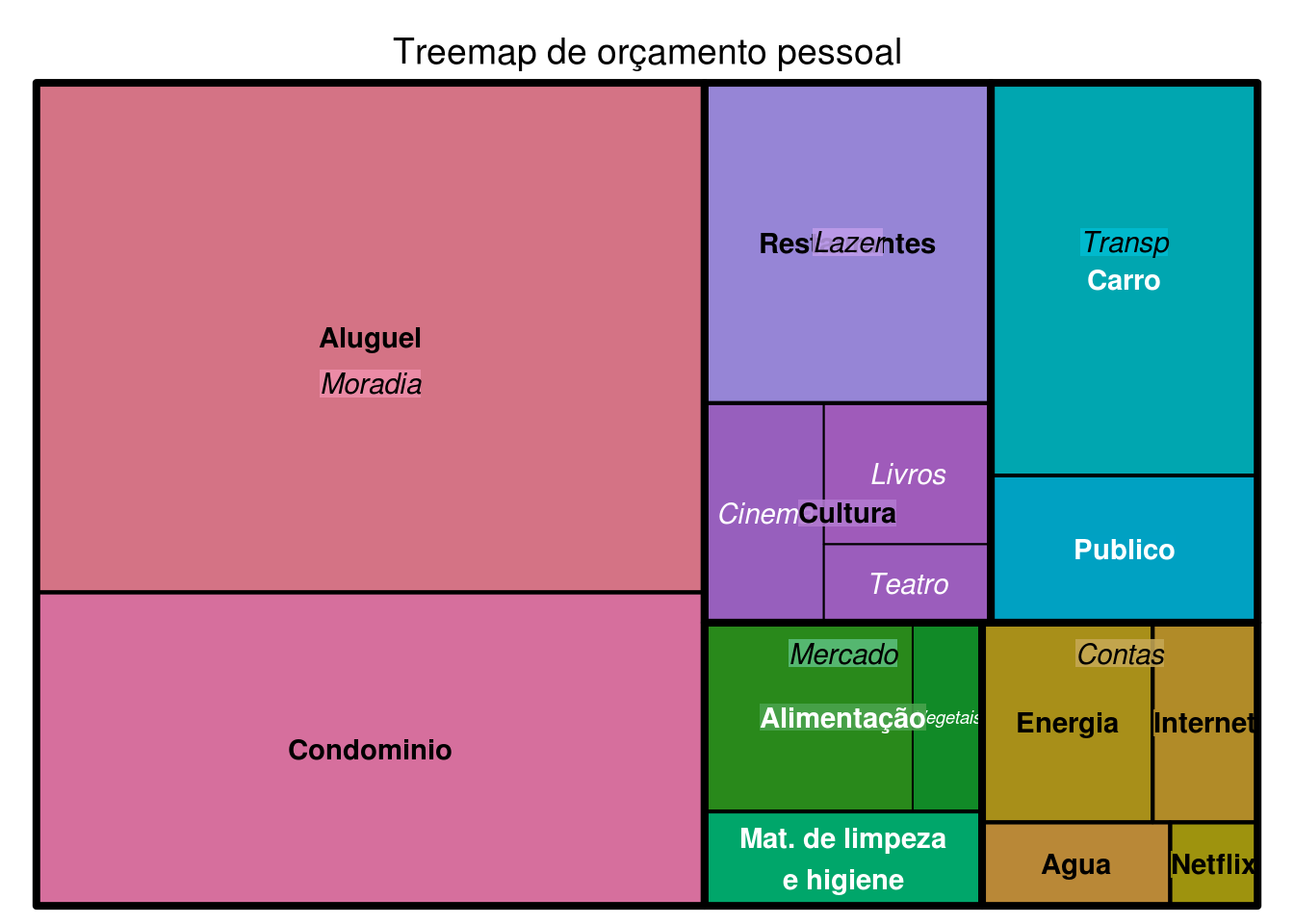
## 6 Transp Carro <NA> 400Conforme os dados mostram, os dados seguem um padrão hierárquico, pois estão em organizados em categorias (nivel1) que possuem subcategorias (nivel2), que por sua vez possuem subhieraquias menores (nivel3).
Qual seria então uma boa maneira de visualizar essa estrutura de dados? Uma alternativa são os treemaps. A função treemap::treemap() também é simples de ser usada: precisamos definir o dataframe no parâmetro dfr, os níveis hierárquicos em index, a variável que define a área dos quadriláteros em vSize e outras customizações:
treemap(orcamento_pessoal,
# definindo os niveis hierarquicos
index = c("nivel1", "nivel2", "nivel3"),
# variavel numerica que define o tamanho dos blocos
vSize = "despesa",
# titulo
title = "Treemap de orçamento pessoal",
# definir estilo da fonte e ajuste vertical para cada um dos niveis hierarquicos
fontface.labels = c("oblique", "bold", "italic"),
ymod.labels = c(0.6, 0, 0)
)
Outra alternativa é o gráfico do tipo sunburst, que lembra um gráfico de pizza.
Para fazer um gráfico sunburst, é preciso concatenar as colunas de níveis hieráquicos com um traço. Observe o exemplo fornecido na documentação do pacote:
# ?sunburst
# exemplo tirado da documentação:
sequences <- read.csv(
system.file("examples/visit-sequences.csv",package="sunburstR")
,header = FALSE
,stringsAsFactors = FALSE
)[1:100,]
# observe a estrutura de dados
head(sequences)## V1 V2
## 1 account-account-account-account-account-account 22781
## 2 account-account-account-account-account-end 3311
## 3 account-account-account-account-account-home 906
## 4 account-account-account-account-account-other 1156
## 5 account-account-account-account-account-product 5969
## 6 account-account-account-account-account-search 692# o sunburst é produzido com a função homônima:
sunburst(sequences)Para concatenar nosso dataframe de orçamento do exemplo, usamos a função tidyr::unite(), que como o nome fala, junta várias colunas em uma só.
orcamento_pessoal_sb <- orcamento_pessoal %>%
unite(hierarquia, nivel1:nivel3, sep = "-")
sunburst(orcamento_pessoal_sb)Percebeu como os níveis 2 que não possuem um nível 4 foram trocados por um NA, prejudicando o visual do gráfico?
Por isso, recomenda-se substituir os NAs por um caracter vazio (“”).
orcamento_pessoal %>%
mutate(nivel3 = ifelse(is.na(nivel3), "", nivel3)) %>%
unite(hierarquia, nivel1:nivel3, sep = "-") %>%
sunburst()4.5 Exercícios
- Carregue os pacotes usados no material deste módulo
plotly
Carregue o dataset
series_ipca_selic.rds.Filtre os dados a partir de 01/01/2000 e faça um gráfico simples de linha dos indicadores, mapeando a coluna de indicador na aesthetic cor. Salve o gráfico no objeto
p2.Transforme o gráfico para interativo usando a função
ggplotly. Brinque com o gráfico: dê zoom em períodos específicos, passe o mouse nas linhas, etc. Confira como ficou a tooltip.Volte ao gráfico original e defina uma aesthetic
textde forma que mostre a data em um formato mm/aaaa, o nome do indicador e seu valor.Salve o gráfico finalizado em um arquivo local com a extensão html.
geom_sf
- Execute o código abaixo para baixar o conjunto de dados da quantidade de servidores civis e total remunerado para os mesmos por estado (dados de Junho/2018):
# https://github.com/sillasgonzaga/postsibpad/blob/master/data/servidores_agregados_por_uf.csv
df_servidores <- read.csv2("https://raw.githubusercontent.com/sillasgonzaga/postsibpad/master/data/servidores_agregados_por_uf.csv")Crie um novo dataframe chamado
df_servidores_estado, que corresponde à junção do dataframebrmap_estado, do pacotebrmap, comdf_servidores.Crie dois mapas: um com os estados coloridos pela quantidade de servidores e outro pelo log da remuneração bruta.